D3 条形图
提示
本文的大部分代码需要依赖 D3.js 库,在写本文时 D3.js 版本为 v7
静态图
官方样例的构建流程概述:
- 处理数据
- 构建比例尺
- 设置柱子的标注信息(当鼠标 hover 在柱子上时会显示相应的信息)
- 绘制条形图的容器(边框和坐标轴)
- 绘制条形图内的柱子
在官方样例中,将绘制静态条形图的核心代码封装为一个通用的函数 function BarChart() 具体解读可以查看这个 Notebook
但是该函数实际上通用性并不足,因为它会使用一些 Observable 平台专有的功能/方法,所以我基于它进行简化(虽然降低了代码的通用性),然后在一般的前端 js 环境复现,完整代码可以查看 这里
除了垂直方向的条形图(也称为柱状图),条形图还有一些很常见的形式,例如 Horizontal 水平方向的条形图,以及 Diverging 发散型的条形图
说明
Diverging 发散型的条形图从外观而言就是条形图的柱子有两个方向,如果柱子是水平的,则柱子可以在 Y 轴的左右两侧;如果柱子是垂直的,则柱子可以在 X 轴的上下两侧。
也就是说发散型的条形图是可以显示正负值的。
以下部分是对这两种条形图的官方样例的解读
水平方向条形图
参考
- 解读的官方样例为 Bar Chart, Horizontal
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其实根据垂直方向的条形图,可以很方便地制作水平方向的条形图,只需要将坐标轴相互调换(并对于相关的元素和方法进行调整)即可
其中有几个地方值得关注和学习参考:
- 之前在垂直条形图中,只能通过
<title>标签为柱子设置标注信息,这样标注内容就只有在鼠标 hover 在柱子上时才显示出来。而现在由于条形图是横向的,与文字阅读方向相同,所以可以通过<text>元素,将标注信息直接显示在相应的柱子上。在为柱子添加上文本标注信息时,样例还考虑到了柱子的长短的问题,会根据柱子的长短,决定标注文本的不同位置和颜色。 - 之前在垂直条形图中,柱子的宽度是基于页面的宽度来划分的。而现在由于条形图是横向的,而页面在垂直方向上滚动很方便,所以理论上柱子的宽度可以取任意值也不影响交互,所以可以有多种方式来设置柱子的「带宽」,可以基于屏幕的高度来计算出柱子的「带宽」;也可以直接设置「带宽」,再来设定 svg 的高度,样例代码中就默认将柱子的「带宽」设置为
25px
以下是相关代码
/**
*
* 设置每个柱子的标注信息
* 根据柱子的长短,决定标注文本的不同位置和颜色
* 如果柱子较长,将标注信息置于柱子上,文本颜色为白色
* 如果柱子较短,将标注信息置于柱子旁边(在条形图的背景上),文本的颜色为黑色
*/
// 之前在垂直条形图中,只有当鼠标 hover 在柱子上才显示的标注信息,
// 💡 而现在由于条形图是横向的,与文字阅读方向相同,所以现在有足够的位置可以直接显示在相应的柱子上
svg.append("g")
// 先默认标注信息都在柱子上,设置文字的颜色
.attr("fill", titleColor)
// 因为默认文本在柱子的最右侧,所以对齐方式设置为 end
// 即文本的 (x, y) 定位坐标是其末尾,文字向左展开
.attr("text-anchor", "end")
.attr("font-family", "sans-serif")
.attr("font-size", 10)
.selectAll("text")
.data(I) // 绑定的数据是表示数据点的索引值(数组),以下会通过索引值来获取各柱子相应标注信息
.join("text")
// 将文本移动到相应的柱子上
.attr("x", i => xScale(X[i])) // 文本的横向坐标,移到柱子的最右侧
.attr("y", i => yScale(Y[i]) + yScale.bandwidth() / 2) // 文本的纵向坐标
.attr("dy", "0.35em")
.attr("dx", -4)
.text(title)
// 最后再基于柱子的长度对文本的定位和颜色进行调整
.call(text =>
// 筛选出较短的柱子所对应的文本
// 当矩形的长度 xScale(X[i]) - xScale(0) 小于 20 时就是较短的柱子
text.filter(i => xScale(X[i]) - xScale(0) < 20) // short bars
.attr("dx", +4) // 将文本稍微向右移动,这样文本就位于条形图的白色背景上(而不是彩色的柱子上)
.attr("fill", titleAltColor) // 所以需要将白色的文字改成黑色的文字
// 而且改变文字的对齐方式为 start,即文本的 (x, y) 定位坐标是其开头,文字向右展开
.attr("text-anchor", "start")
);
发散型的条形图
参考
- 解读的官方样例为 Bar Chart, Diverging
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中有几个地方值得关注和学习参考:
- 发散型的条形图可以用于展示具有正负值的数据,样例中将正负值数据映射为不同的颜色。
采用的 color schema 是d3.schemePiYG,该配色方案从一个色谱里进行采样,构成一系列有明显对比度的色值。它是一个包含 12 个元素的数组,除了前 3 个元素(前 3 个元素为空,因为采样较少,无法保证颜色有足够的对比度,实用性较低?)其他元素都是嵌套数组(里面的元素都是表示颜色值的字符串)
color schema d3.schemePiYG
可以使用d3.schemePiYG[k]来获取一种配色方案,k的取值范围是3至11。默认采用d3.schemePiYG[3]作为配色方案,它返回一个数组["#e9a3c9", "#f7f7f7", "#a1d76a"]其中包含 3 个元素(但在该实例中,只需要两个色值,所以取数组的第一个和最后一个元素,它们的对比度最明显,便于区分两种不同的类别),每个元素都是一个表示色值的字符串提示
关于 color schema 配色方案的更多使用说明可以参考官方文档
- 因为发散型的条形图中柱子可以向左或向右延伸,所以页面的很多图形元素都需要根据柱子的正负值来进行调整
其中样例中有一个比较实用的做法值得学习借鉴是构建一个 InternMap 对象,用于将不同的类别(地名)映射到其对应数据值,便于直接根据类别判断其对应的柱子的正负值。
例如在绘制 Y 轴时,会根据差值的正负值,来判断是否需要修改相应的坐标轴的刻度值的位置(默认在左侧,因为负值的柱子向左侧绘制的,所以需要把刻度值移到 Y 轴的右侧)。
InternMap 对象可以理解为一个普通的对象,但是有一些 D3.js 添加的额外属性,也是由一系列的键值对构成,其中键是类别(即地名),值则是对应的人口(2019 年 - 2010 年)差值
使用方法d3.rollup(iterable, reduce, ...keys)基于指定的属性keys进行分组,并对各分组进行reduce「压缩降维」,最后返回一个InternMap对象- 第一个参数
iterable是可迭代对象,即数据集 - 第二个参数
reduce是对分组进行压缩的函数,每个分组会依次调用该函数(入参就是包含各个分组元素的数组),返回值会作为 InternMap 对象中(各分组的)键值对中的值 - 余下的参数
...keys是一系列返回分组依据
jsYX = d3.rollup(I, ([i]) => X[i], i => Y[i])
该实例是根据地名Y[i]进行分组,然后再对每个组调用 reduce 函数([i]) => X[i]进行「压缩降维」 每次 reduce 函数时,传入的都是一个数组(由该分组的所有元素组成,即该分组的索引值构成的一个数组),而本实例中,每个分组就只有一个元素(一个地名归为一组),所以这里使用[i]直接解构出相应的索引值,并通过X[i]来获取该地方对应的人口(2019 年- 2010 年)差值,因此最终每个分组「压缩降维」得到的数据是该地方对应的人口(2019 年- 2010 年)差值
坐标轴、刻度值、标注信息的定位要根据柱子的正负值进行相应的调整,以下是相关代码 - 第一个参数
svg.append("g")
.attr("transform", `translate(${xScale(0)},0)`) // 将纵坐标轴容器定位到横坐标轴的零点位置
.call(yAxis)
.call(g =>
// 选择所有的刻度值
g.selectAll(".tick text")
.filter(y => YX.get(y) < 0) // 筛选出所对应的柱子的值为负值的刻度值
// 刻度值默认在纵轴的左侧,将这些刻度值调整到纵轴的右侧
.attr("text-anchor", "start") // 将文本的对齐方式改变为 start
.attr("x", 6) // 并设置一点水平向右的偏移(6px)
);
响应性
实现图表随页面大小响应式变化的功能可以参考 《D3 散点图》响应性的方案二
交互性
缩放平移
当数据较多时,可以在条形图的 X 轴方向添加缩放和平移功能。
主要使用 D3 zoom 模块,支持双击条形图,或使用鼠标滚轮(或在触屏设备上双指捏合)来进行缩放。
参考
- 解读的官方样例为 Zoomable Bar Chart
但是这个示例的必要性有点牵强的——因为当你可以轻松地一次性将条形图的所有柱子展示出来时,其实该示例并不需要缩放功能,只是作为简单的演示。 - 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中关于缩放的核心代码如下
// 参考自 https://observablehq.com/@benbinbin/zoomable-bar-chart
// 与缩放操作相关的核心逻辑
// 封装为一个函数
function zoom(svg) {
// 缩放事件的回调函数
function zoomed(event) {
// 更改横轴的比例尺
// 调用缩放变换对象 event.transform 的方法 event.transform.applyX(d)
// 传入的是原始的横坐标 d 通过缩放变换对象处理,返回变换后的坐标
// 所以 [xmin, xmax].map(d => event.transform.applyX(d)) 是基于原来的横轴值域,求出缩放变换后的新值域
// 然后修改横坐标轴的比例尺的值域 x.range([newXmin, newXmax])
x.range(
[margin.left, width - margin.right].map((d) => event.transform.applyX(d))
);
// s使用新的比例尺调整条形图的柱子的定位(通过改变柱子的左上角的 x 值)
// 以及调整条形图的柱子的宽度,通过新的比例尺 x.bandwidth() 获取
svg
.selectAll(".bars rect")
.attr("x", (d) => x(d.name))
.attr("width", x.bandwidth());
// 使用新的比例尺重新绘制横坐标轴
svg.selectAll(".x-axis").call(xAxis);
}
// 设置平移范围
// extent 是一个嵌套数组,第一个元素是条形图的矩形区域的左上角,第二个元素是右下角
const extent = [
[margin.left, margin.top],
[width - margin.right, height - margin.top]
];
// 创建缩放器
const zoomer = d3
.zoom()
// 约束缩放比例的范围,默认值是 [0, ∞]
// 入参是一个数组 [1, 8] 表示最小的缩放比例是 1 倍,最大的缩放比例是 8 倍
.scaleExtent([1, 8])
// 约束平移的范围 translate extent,默认值是 [[-∞, -∞], [+∞, +∞]]
// 这里设置为 extent 正好是条形图的柱子区域
// 所以即使放大后,画布也只能在最左边的柱子和最右边的柱子之间移动
.translateExtent(extent)
// 设置视图范围 viewport extent
// 如果缩放器绑定的是 svg,则视图范围 viewport extent 默认是 viewBox
// 这里「校正」为条形图的柱子区域(不包含 margin 的区域)
.extent(extent)
.on("zoom", zoomed); // 缩放事件的回调函数
// 🔎 以上提及的视图范围 viewport extent 和平移范围 translate extent 这两个概念,具体可以查看 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-interact
svg.call(zoomer); // 为 svg 添加缩放事件监听器
}
此外基于原始的样例,在解读和复现时还进行了一个设计上的小优化。当条形图放大时,柱子会「延伸」到纵轴后,阻碍纵轴的显示。所以在 svg 的左侧添加一个白色的矩形,作为纵坐标轴的「背景」。
// ⚠️ 在添加白色的矩形时应该注意先后顺序
// 因为 svg 绘制的先后影响图像元素的叠放顺序
// 需要先绘制完柱子和横坐标轴
// 再绘制白色的矩形
// 最后才绘制纵坐标轴,这样元素的层叠顺序才会符合预期的效果
/**
*
* 绘制条形图
*
*/
// 绘制条形图内的柱子
svg
.append("g")
.attr("class", "bars") // 为柱子的容器添加一个名为 "bars" 的 class 类名
// ...
// 绘制横坐标轴
svg
.append("g")
.attr("class", "x-axis") // 为横坐标轴容器添加一个名为 "x-axis" 的 class 类名
.call(xAxis); // 调用坐标轴(对象)方法,将坐标轴在相应容器内部渲染出来
// 在 svg 的左侧添加一个白色的矩形
// 作为纵坐标轴的「背景」
// 这样在放大条形图时,柱子即使会「延伸」到纵轴后,也会被白色矩形掩盖,并不会阻碍纵轴的显示
svg
.append("rect")
.attr("x", 0)
.attr("y", 0)
.attr("width", margin.left)
.attr("height", height)
.attr("fill", "white");
// 绘制纵坐标轴
svg
.append("g")
.attr("class", "y-axis") // 为纵坐标轴容器添加一个名为 "y-axis" 的 class 类名
.call(yAxis); // 调用坐标轴(对象)方法,将坐标轴在相应容器内部渲染出来
层级下钻
使用条形图展示具有层级结构的数据时,可以添加点击下钻的功能,即点击条形图中的某一个柱子,可以查看其子层级的情况。
参考
- 解读的官方样例为 Hierarchical Bar Chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中对于层级数据的处理主要使用 d3-hierarchy 模块,核心代码如下
// 通过方法 d3.hierarchy() 对数据进行处理,基于树形数据 data 计算层级结构
// 构建出各层级的节点(并为节点添加相应的属性)
root = d3.hierarchy(data)
// node.sum() 方法为所有节点分别添加 node.value 属性
// 该示例中 node.value 表示当前节点所在分支后的所有叶子节点所绑定的值的**累计值**
// 具体作用可以参考官方文档 https://github.com/d3/d3-hierarchy#node_sum
.sum(d => d.value)
// node.sort() 方法对同层级的节点进行排序
// 这里是按照前面算到的各节点的累计值 node.value 进行降序 descending 排序
// 具体作用可以参考官方文档 https://github.com/d3/d3-hierarchy#node_sort
.sort((a, b) => b.value - a.value)
// node.eachAfter(callback) 方法以后序遍历的顺序让节点均调用一次函数回调函数 callback
// 该示例中(从叶子节点开始)为所有节点添加一个属性 index
// 用于下钻时的动效过渡,作为同层级的节点的的唯一标识符,以便在过渡动效中实现柱子的堆叠和交错的效果
// index 的值根据节点是否具有父节点 d.parent 来决定
// 如果有父节点则将父节点的 index 值加一,同时将此时的父节点的 index 值作为该子节点的 index 值(如果父节点本来没有 index 值,则初始值为 0,所以此时所遍历的子节点的 index 也是 0)
// 如果没有父节点(根节点)则它的 index 值为 0
// 💡 因为是后序遍历,所以在遍历一个分支上的子节点时,所对应的那个「父节点」index 其实 是作为一个「指针」,临时记录所遍历的当前的子节点的 index 值,让下一个所遍历的子节点可以根据前一个子节点的 index 值依次递增 1
// 等到子节点遍历完成后,这个「父节点」和同层级的节点才会进入遍历,它的 index 值就会被重新设置,根据是否有父节点 parent 和在同级节点中的位置(遍历的顺序)来设置 index 的值
.eachAfter(d => {
d.index = d.parent ? (d.parent.index = d.parent.index + 1 || 0) : 0
})
另外在交互时,有一个值得学习的做法是使用了 transition.transition() 创建两个过渡管理器,通过它们来创建的过渡动效是先后连续的,依据这个方法和思路,可以构建更复杂的动画,其核心代码如下:
// (在 svg 上)定义两个先后执行的过渡管理器
const transition1 = svg.transition().duration(duration);
// (通过第二个过渡管理器所创建的)过渡会在通过前一个过渡管理器所创建的过渡**结束后**才会开始执行
const transition2 = transition1.transition();
提示
与过渡动效相关的 D3 模块是 d3-transition
动效
可追踪条带的过渡
为条形图添加过渡动效,可以利用物体恒存 object constancy 让用户更容易地留意和理解数据是如何变化的。
物体恒存
物体恒存 object constancy 是指一个图像元素(表示一个数据点)可以在过渡变换时通过视觉跟踪。这样可以减轻认知负担,这是因为连续的动画可以让我们利用对运动的前注意处理 pre-attentive processing of motion 来识别物体,而不仅仅在图像(数据)改变后通过扫视图表的标注信息来识别。
参考样例一
- 解读的官方样例为 Bar Chart Transitions
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中更新排序方式并刷新页面元素的核心代码如下:
function update(data, {
// 横坐标轴的定义域范围
// 对于条形图而言,其横坐标定义域范围就是一个数组,其中的每一个元素都是一个不同的类别
xDomain, // an array of (ordinal) x-values
// 纵坐标轴的定义域范围 [ymin, ymax]
yDomain, // [ymin, ymax]
duration = initialDuration, // 过渡时间
delay = initialDelay // 为每一个图像元素(柱子)设置过渡动效开始的延迟时间
} = {}) {
/**
*
* 重新处理数据
*
*/
// 每次更新都需要对数据重新处理
// 因为需要重新构建横坐标轴的定义域范围(各元素/类别的排序不同了)
// 虽然在该示例中,数据并没有发生变化,只是数据集中数据点的排序发生了变化,通过完全的重新计算处理,虽然需要增加一些性能开销,但是可以让该示例的代码更具有通用性。因为这样的代码就不单纯是适用于改变数据的排序,还可以适用于数据的(筛选)增删的场景
// 通过 d3.map() 迭代函数,使用相应的 accessor function 访问函数从原始数据 data 中获取相应的值
const X = d3.map(data, x);
const Y = d3.map(data, y);
/**
*
* 重新构建比例尺
*
*/
// 计算坐标轴的定义域范围
// 如果调用函数时没有传入横坐标轴的定义域范围 xDomain,则将其先设置为由所有数据点的 x 值构成的数组
if (xDomain === undefined) xDomain = X;
// 然后基于 xDomain 值创建一个 InternSet 对象,以便去重
// 这样所得的 xDomain 里的元素都是唯一的,作为横坐标轴的定义域(分类的依据)
// InternSet 对象其实是属于 JavaScript 的数据类型**集合 set** 的一种
// 在 Set 中迭代总是按照值插入的顺序进行的,所以我们不能说这些集合是无序的(但是我们不能对元素进行重新排序,也不能直接按其编号来获取元素,但它是一个可迭代对象,有相应的其他方法来遍历其中的元素)
// 关于 set 集合这种数据类型可以参考 https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Set
// 所以每次对原数据进行重新排序后,再重新构建 InterSet 对象,其中元素/分类的顺序就会相应改变
// 再以新构建 InterSet 对象作为横坐标的定义域,这样就可以实现各类别的重新顺序
xDomain = new d3.InternSet(xDomain);
// 纵坐标轴的定义域 [ymin, ymax] 其中最大值 ymax 使用方法 d3.max(Y) 从所有数据点的 y 值获取
if (yDomain === undefined) yDomain = [0, d3.max(Y)];
// 这里还做了一步数据清洗
const I = d3.range(X.length).filter(i => xDomain.has(X[i]));
// 更新坐标轴对象(通过重新设定各坐标轴的定义域范围)
xScale.domain(xDomain);
yScale.domain(yDomain);
// 创建一个过渡管理器
// 并配置过渡时间
const t = svg.transition().duration(duration);
// 为矩形柱子元素重新绑定数据(索引值)
rect = rect
// 为了复用元素(制作连续的过渡动画),所以需要设置第二个参数(称为 key 函数)
// key 函数会被元素和数据分别依次调用,最后返回一个字符串作为标识符
// 分别计算出表示各元素的标识符,和表示数据的标识符,如果两者的键匹配,则它们就会配对绑定
.data(I, function (i) {
// key 函数
// 如果是元素调用该函数时 this.tagName === "rect" 为 true,则返回元素原来就设定的属性 this.key 作为标识符(就是该柱子所对应的字母名称)
// 如果是数据(索引值)调用该函数时 this.tagName === "rect" 为 false,则返回数据(索引值)在新的排序下所对应的字母的名称 X[i]
return this.tagName === "rect" ? this.key : X[i];
})
// 调用 join() 方法更新页面的元素
// 该方法最后会返回 entering 选择集和 updating 选择集合并在一起的选择集
.join(
// 虽然在本示例中数据并没有增删,只是位置进行了更新
// 但是这里依然手动设置 enterinentering 选择集、exiting 选择集和 updating 选择集的处理方法
// 可以让代码更通用
// 处理 entering 选择集的元素
enter => enter.append("rect") // 将该选择集中的虚拟元素以 <rect> 元素的形式添加到页面上
// 为新增的元素添加一个 key 属性,属性值采用相应的字母名称,作为元素的唯一标识符
// 在之后的过渡动效中使用,以便程序更准确地(设置移动位置)复用这些元素
.property("key", i => X[i]) // for future transitions
// 然后调用 position() 方法设置新增的矩形柱元素的 (x, y) 坐标以及宽高
.call(position, i => xScale(X[i]), yScale(0))
// 设置一个 CSS 属性 mix-blend-mode,设置为 multiple
// 当新增的柱子插入的到页面时,与已有的柱子之间重叠时会产生加深颜色的效果
.style("mix-blend-mode", "multiply")
.call(enter => enter.append("title")), // 设置新增柱子的提示信息
// 处理 updating 选择集的元素
// 对于在页面上原有的且需要保留的元素先不做处理
// 直接返回该选择集
update => update,
// 处理 exting 选择集的元素
// 移除新数据中没有的相应柱子
// 使用过渡管理器 t 的配置,为该过程该过程创建一个过渡
exit => exit.transition(t)
.delay(delay) // 而且设置一个过渡延迟
// 过渡的效果是从原来的位置向下缩小移除
.attr("y", yScale(0)) // 过渡的最终矩形的纵坐标是在纵坐标的零点
.attr("height", 0) // 过渡的最终矩形的高度是 0
.remove() // 将元素移除
);
// 这里更新柱子(包含 updating 选择集和 entering 选择集)的提示信息
// 其中上面在更新元素所绑定的数据时,对 entering 选择集的元素设置了 <title> 元素,所以该选择集的元素的提示信息已经是最新的了
// 而 updating 选择集中是保留下来的元素,所以提示信息并不需要改变
// 这一步似乎是冗余的,可以不用
rect.select("title")
.text(i => [X[i], format(Y[i])].join("\n"));
/**
*
* 基于更新后的数据来调整页面的柱子
* 以及重新绘制坐标轴
*
*/
// 更新矩形柱子的位置和尺寸
// 使用过渡管理器 t 的配置,为该过程该过程创建一个过渡
rect.transition(t)
// 而且通过 delay 函数为每一个柱子设置不同的过渡延迟
// 实现交错过渡移动的效果
.delay(delay)
// 调用 position() 方法更新矩形柱子的位置和尺寸
// 传入柱子的 x 值访问函数和 y 值访问函数(采用新的坐标轴比例尺,计算出新的坐标值)
.call(position, i => xScale(X[i]), i => yScale(Y[i]));
// 更新横坐标轴
// 使用过渡管理器 t 的配置,为该过程该过程创建一个过渡
xGroup.transition(t)
// 调用坐标轴(对象)方法,将坐标轴在相应容器内部渲染出来(而且会自动删除或复用已有的坐标轴)
.call(xAxis)
// 而且通过 delay 函数为每一个 tick 刻度(包含刻度线和对应的刻度值)设置了不同的延迟
// 这里假设刻度和柱子是一一对应的,这样在视觉上看起来才会像是刻度值随着柱子同步移动更新的
.call(g => g.selectAll(".tick").delay(delay));
// 更新纵坐标轴
// Transition the y-axis, then post process for grid lines etc.
// 使用过渡管理器 t 的配置,为该过程该过程创建一个过渡
yGroup.transition(t)
// 调用坐标轴(对象)方法,将坐标轴在相应容器内部渲染出来(而且会自动删除或复用已有的坐标轴)
.call(yAxis)
.selection() // 选中过渡管理器所绑定的选择集
// 传入的参数 g 就是该选择集(该选择集就包含纵坐标轴的容器 <g> 元素)
// 然后选中并删除坐标轴线(具有 domain 类名)
.call(g => g.select(".domain").remove())
// 调整参考线
// 因为在本示例中仅是数据的排序发生变化,而并没有增删数据,所以数据的范围并不变
// 即纵坐标轴的定义域范围并不会改变,实际无需重绘/调整参考线
// 但是这里添加这一段代码可以让该示例更通用
.call(g => {
// 先选中所有的刻度容器(具有 tick 类名,包含刻度线和刻度值)
// 再进行二次选择,选中其中带有 grid 的类名的元素(就是更新纵坐标轴后依然保留下来的那些参考线)
// 关于次级选择的工作原理和结构可以参考 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-binding#次级选择
// 在更新纵坐标轴后,如果刻度(容器)是复用原来的,那么二次选择后的选择集中就包含参考线元素;如果刻度(容器)是新增的,那么二次选择后选择集就是空的
// 接着先为选择集绑定数据 .data([,]) 该数组只有一个元素,因为每个刻度容器里只需要绘制一条参考线。这样所有的选择集(的第一个元素)会绑定一个数据,对于选择集为空的情况,就会创建一个虚拟元素来与数据匹配,这个虚拟 DOM 就会进入 entering 选择集
// 因为这里是为了在页面添加元素(参考线),所以绑定数据的具体值是无所谓的,在这个示例中相当于为元素绑定一个 undefined 作为数据
// 然后调用 join(grid) 方法,只传入第一个参数,即只对 entering 选择集进行处理,即调用 grid() 函数为空的选择集添加上一个 <line> 元素(参考线)
g.selectAll(".tick").selectAll(".grid").data([,]).join(grid)
});
}
另外为了降低(在过渡时)因为元素重叠而让视觉跟踪丢失的可能,为矩形柱子元素设置了一个 CSS 属性 mix-blend-mode,该属性值设置为 multiple,这样每当柱子之间发生重叠时就会产生加深颜色的效果,相关代码如下
// 绘制条形图内的柱子
let rect = svg.append("g")
// ...
// 💡 为元素设置一个 CSS 属性 mix-blend-mode,设置为 multiple
// 可以在过渡动画中,当柱子之间重叠时产生加深颜色的效果
// 关于该 CSS 属性具体可以参考 https://developer.mozilla.org/zh-CN/docs/Web/CSS/mix-blend-mode
.style("mix-blend-mode", "multiply")
// ...
参考样例二
- 解读的官方样例为 Bar Chart Race
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
在该示例中基于简单的数据(从 2000 年到 2019 年之间一系列的全球顶级品牌的价值),通过在两个相应(年份)的真实数据点之间使用线性插值法计算出更多的数量,用以创建更流畅的动画
线性插值法
关于线性插值法的公式具体解释可以参考这一篇笔记:线性插值法
其核心代码如下
// 计算更多时间点的数据(对应于过渡动画的「每一帧」)
// 例如当 k=10 时,即在两个(相邻年份)原始数据之间插入 9 个数据点
// 所以原来从 2000 至 2019 年原有 20 个数据点,在相邻的年份之间都插入 9 个数据点
// ✨ 最终 keyframes 数组共有 20+19*9=191 个元素
// ✨ 而且每一个元素的形式都是 [date, data] 二元数组,第一个值 date 就是时间点;第二个值 data 就是一个包含公司价值的对象数组,具有 173 个元素(即每一个时间点的数据都包含所有的公司的价值数据)
const keyframes = []; // 容器是每一帧(对应于某个日期的数据)
let ka, a, kb, b;
// d3.pairs(iterable[, reducer]) 方法将相邻元素两两配对,生成一个新的数组
// 更多关于 d3.rollup() 方法的信息可以参考官方文档 https://github.com/d3/d3-array/#pairs 或笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-process#转换 的相关部分
// 然后遍历所得的数组(每一个元素都是一个二维数组)
// 并通过解构数组得到相应的数据
// ka 是年份(日期对象),a 是该年份(分组)所对应的数据
// kb 是紧接着 ka 下一年的年份(日期对象),b 就是该年份对应的数据
for ([[ka, a], [kb, b]] of d3.pairs(datevalues)) {
// 计算插值数据
// 其中 k 表示在两个(时间间隔跨度为年份)原始数据之间需要插值的数量
// k 的值越大,表示插值的数量越多,这样(各横向柱子的长度变化)过渡动画就显得越「流畅」
// 例如当 k=10 时,则插入 9 个数据
// ⚠️ 遍历时从 i=0 开始,到 i<k(所以只包含下限,不包含上限)
// 即 push 到 keygrames 数组的原始数据只有 [ka, a]
for (let i = 0; i < k; ++i) {
// 使用 linear interpolation 线性插值法,估算出给定日期 date 所对应的数据
// 关于线性插值法的公式具体解释可以参考 https://datavis-note.benbinbin.com/article/theory/algorithm/linear-interpolation
// t 是当前创建的插值所对应的归一化距离,其范围是 (0, 1)
// 那么两个原始数据 a 和 b 就分别位于 [0, 1] 的两个端点
const t = i / k;
// 计算插值,并 push 到 keyframes 数组中
keyframes.push([
// 该插值所对应的的日期(对象)
new Date(ka * (1 - t) + kb * t),
// ✨ 这里调用 rank() 函数来估算出在当前日期**所有公司**的价值
// 其中在方法 rank(valueFunc) 传入的参数 valueFunc 是一个函数,用于获取给定公司(名称)的价值
// 这个函数的核心就是用线性插值法 $y=y_{0}(1-t)+y_{1}t$ 基于该公司在两个(年份)时间点的已知价值,估算出(在这两个时间点之间)特定时间点(用归一化距离 t 表示)该公司的价值
// 但是看起来比价复杂,因为其中还包含一些条件判断逻辑
// 因为每一年的数据中,并非包含所有公司的价值,所以 a.get(name) 和 b.get(name) 从原数据中获取指定公司的价值时可能返回 undefined,此时就假设该公司在该年份的价值为 0,
rank(name => (a.get(name) || 0) * (1 - t) + (b.get(name) || 0) * t)
]);
}
// ⚠️ 因为前面遍历插值过程中,只包含下限,不包含上限
// 所以最后还需要将原始数据里的最后一个数据 [kb, b] 追加进去,即 2019 年的数据
keyframes.push([new Date(kb), rank(name => b.get(name) || 0)]);
}
在该实例中对数据进行了大量的转换处理,从原始数据中构建出绘图和制作动画所需的格式,其中使用的方法也值得学习。以下是主要使用的方法:
d3.pairs(iterable[, reducer])方法将相邻元素两两配对,生成一个新的数组
更多关于d3.rollup()方法的信息可以参考官方文档或笔记的相关部分d3.groups(iterable, ...keys)对展平的数组进行分组转换
第一参数iterable是需要分组的可迭代对象,即展平的数组
第二个及之后的一系列参数是分组依据
最后返回一个数组,其中每一个元素就是一个分组d3.rollup(iterable, reduce, ...keys)基于指定的属性进行分组,并对各分组进行「压缩降维」,返回一个 InternMap 对象
第一个参数是需要进行转换的可迭代对象
第二个参数是对分组进行压缩的函数,每个分组会依次调用该函数(入参就是包含各个分组元素的数组),返回值会作为 InternMap 对象中(各分组的)键值对中的值
余下的参数...keys是一系列的分组依据(依次基于这些函数的返回值对数据进行「嵌套式」的分组)
更多关于d3.rollup()方法的信息可以参考官方文档或笔记的相关部分arr.flatMap(mapFunc)方法会先对数组的每个元素进行映射,然后再展平(一级)这个嵌套数组
该实例创建动画的方法也是值得学习的,根据不同时间点的数据更新页面的图像元素,就像是在绘制动画的「关键帧」,因此所使用的变量名称是 keyframe,并使用过渡动效将这些「关键帧」连起来就构成了连续流程的动画。以下是核心代码:
// 将每一个日期(时间点)的数据依次更新到页面上,并在数据更新时应用一些过渡动效
// 根据不同时间点的数据更新页面的图像元素时,就像是在绘制动画的「关键帧」
// 因此所使用的变量名称是 keyframe
// 通过过渡动效将这些「关键帧」连起来就构成了连续流程的动画
// 这里使用立即执行函数 IIFE,因为需要在 for 遍历中使用 await,保证在每一次数据更新时,前一个过渡已经执行完成了,所以需要用 IIFE 包裹一层,在前面添加 async 标记,异步调用整个代码块
(async function () {
for (const keyframe of keyframes) {
// 每次循环都创建一个新的过渡管理器
const transition = svg.transition()
.duration(duration) // 设置过渡持续时间
.ease(d3.easeLinear); // 设置过渡的缓动函数
// 这里先要更新横轴比例尺的定义域
// 以(当前时间点)新数据的最大值作为定义域的最大值
// 后面就会使用新的比例尺更新坐标轴
x.domain([0, keyframe[1][0].value]);
// 依次调用函数并传入相应的参数,更新相应的图像元素
updateAxis(keyframe, transition);
updateBars(keyframe, transition);
updateLabels(keyframe, transition);
updateTicker(keyframe, transition);
// 等待当前的过渡管理器 transition 所创建的过渡都结束时(会抛出 end 事件)
// 再执行下一次循环
// transition.end() 方法返回的是一个 Promise,所以这里使用 await 来等待异步操作的完成
await transition.end();
}
})()
分组条形图与堆叠条形图的转换
参考
- 解读的官方样例为 Stacked-to-Grouped Bars
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
该例子实现了堆叠条形图与分组条形图之间的转换,由于这两个类型的条形图可以共用同一套数据(它们所需要的数据结构是相同的,都是一个嵌套数组),所以在该例子中条形图所绑定的元素是由堆叠生成器所生成的数据(并经过一些额外的处理),虽然该数据是为了更方便地绘制堆叠图,但是也可以通过必要的计算转换即可用于绘制分组条形图
另外一点值得学习的参考的是,该例子为条形图类型转换添加过渡动效,利用物体恒存 object constancy 让用户追踪条带(各部分)的变化,更容易地留意和理解数据是如何在不同的可视化图表中变化的。
拓展阅读
关于如何为数据可视化设计过渡动效,可以参考 Heer and Robertson 的这一篇论文 Animated Transitions in Statistical Data Graphics
以下是条形图类型转换的相关代码
/**
*
* 堆叠条形图和分组条形图之间的切换
*
*/
// 调用以下方法转换为分组条形图
function transitionGrouped() {
// 更改纵坐标轴比例尺的定义域
// 将定义域的上限(从 y1Max)改为 yMax,它是所有原始数据点中的最大值
y.domain([0, yMax]);
// 为更改(矩形)图形元素的一些属性添加过渡动效,以便利用物体恒存 object constancy 让用户追踪条带(各部分)的变化
// 通过 selection.transition() 创建过渡管理器(在以下代码中 rect 变量就是条形图中包含所有 <rect> 元素的选择集)
// 过渡管理器和选择集类似,有相似的方法,例如为选中的 DOM 元素设置样式属性
// 使用 d3-transition 模块
// 具体参考官方文档 https://d3js.org/d3-transition 或 https://github.com/d3/d3-transition
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-transition
rect.transition()
.duration(500) // 过渡时长为 500ms
// 设置过渡的延迟启动时间,单位是毫秒 ms
// 延迟时间是动态的(即不是固定值,每个元素的过渡延迟时间都不同,根据其索引值 i 计算得到)
// 相邻元素之间相差 20ms,从视觉上来看就会是条形图的各个条带**从左往右**依次开始进行变换(而不是统一开始)
.delay((d, i) => i * 20)
// 设置条带 <rect> 元素的的左上角在横轴的定位 x(过渡的目标值/最终值)
// 由于转换到分组条形图,所以每个矩形(条带)在横轴上的定位与两个值相关:
// * 该条带所属的组别(大类),在该示例中以 0 到 57 的数字来表示类别,正好和元素(在选择集分组中的)索引值 i 相对应
// * 该条带在该组的区间中的次序,由它所属的系列(子类)决定,可以通过所绑定数据(一个三元数组)的第三个元素获取,即以下代码中的 d[2]
// 而横坐标比例尺 x 是将 58 个类别(类别以数字表示,从 0 到 57)映射到 svg 元素的宽度
// 所以通过横坐标轴比例尺 x(i) 进行映射,可以得到相应组别(大类)在横坐标上的位置
// 由于 x.bandwidth 是每个分组区间的宽度,则 x.bandwidth() / n 就是每个条带的宽度
// 再通过计算 x.bandwidth() / n * d[2] 可以知道该条带在该组区间中的位置
.attr("x", (d, i) => x(i) + x.bandwidth() / n * d[2])
// 设置每个条带的宽度(过渡的目标值/最终值)
.attr("width", x.bandwidth() / n)
// 💡 这里通过 transition.transition() 基于原有的过渡管理器所绑定的选择集合,创建一个新的过渡管理器
// 💡 新的过渡管理器会**继承了原有过渡的名称、时间、缓动函数等配置**
// 💡 而且新的过渡会**在前一个过渡结束后开始执行**
// 💡 一般通过该方法为同一个选择集合设置一系列**依次执行的过渡动效**
// 前面的变更是条带的横坐标轴的定位和宽度
// 接着下面的变更是条带的纵坐标轴的定位和高度
// 所以从视觉上来看,条形图从左往右的条带依次先在横轴上发生变换,再在纵轴上发生变换
.transition()
// 设置条带 <rect> 元素的的左上角在纵轴的定位 y(过渡的目标值/最终值)
// ⚠️ 由于元素所绑定的数据 d(一个三元数组)**适用于堆叠条形图**,而这里绘制的是分组条形图
// ⚠️ 所以需要对数据进行计算转换,由于 d[1] 是堆叠的上边界,而 d[0] 是堆叠的下边界
// ⚠️ 那么两者的差值 d[1] - d[0] 再通过比例尺 y 进行映射 y(d[1] - d[0]) 就是堆叠小矩形的高度
// ⚠️ 由于前面已经更改纵坐标轴比例尺的定义域,所以这里 y(d[1] - d[0]) 的映射结果就是条带的高度
// 正是需要将其作为 <rect> 元素的的左上角在纵轴的定位
.attr("y", d => y(d[1] - d[0]))
// 设置条带的高度(过渡的目标值/最终值)
// ⚠️ 同样需要注意所绑定的数据 d(一个三元数组)是适用于堆叠条形图的
// 由于 d[1] 是堆叠的上边界,该值并不是(分组条形图)条带所对应的数据
// 需要作差 d[1] - d[0] 减去其堆叠的下边界,才「还原」出条带所对应的真实数据
// 然后通过 y(0) - y(d[1] - d[0]) 计算出条带的高度
// ⚠️ 应该特别留意纵坐标轴的值域(可视化属性,这里是长度)范围 [bottom, top]
// 由于 svg 的坐标体系中向下和向右是正方向,和我们日常使用的不一致
// 所以这里的值域范围需要采用从下往上与定义域进行映射
.attr("height", d => y(0) - y(d[1] - d[0]));
}
// 调用以下方法转化为堆叠条形图
function transitionStacked() {
// 更改纵坐标轴比例尺的定义域
// 将定义域的上限(从 yMax)改为 y1Max,它是堆叠后的小矩形的(上边界)最大值,即堆叠条形图中最长的条带的 y 值
y.domain([0, y1Max]);
// 变换为堆叠条形图
// 通过 selection.transition() 创建过渡管理器,为更改图形元素的一些属性添加过渡动效
rect.transition()
.duration(500) // 过渡时长为 500ms
.delay((d, i) => i * 20) // 设置过渡的延迟启动时间,每个元素的延迟时间是动态计算得到的
// 设置堆叠小矩形 <rect> 元素的的左上角在纵轴的定位 y(过渡的目标值/最终值)
// 元素所绑定的数据 d(一个三元数组)中第二个元素 d[1] 是堆叠的上边界
.attr("y", d => y(d[1]))
// 设置小矩形的高度(过渡的目标值/最终值)
// 由于 d[1] 是堆叠的上边界,而 d[0] 是堆叠的下边界
// 那么两者的差值 d[1] - d[0] 再通过比例尺 y 进行映射 y(d[1] - d[0]) 就是堆叠小矩形的高度
.attr("height", d => y(d[0]) - y(d[1]))
// 通过 transition.transition() 基于原有的过渡管理器所绑定的选择集合,创建一个新的过渡管理器
// 新的过渡会在前一个过渡结束后开始执行
// 前面的变更是条带的纵坐标轴的定位和高度
// 接着下面的变更是条带的横坐标轴的定位和宽度
// 所以从视觉上来看,条形图从左往右的条带依次先在纵上发生变换,再在横轴上发生变换
.transition()
// 设置条带 <rect> 元素的的左上角在横轴的定位 x(过渡的目标值/最终值)
// 由于转换到堆叠条形图,所以每个小矩形在横轴上的定位与它所属的条带相关
// 在该示例中以 0 到 57 的数字来表示条带的名称,正好和元素(在选择集分组中的)索引值 i 相对应
.attr("x", (d, i) => x(i))
// 设置每个条带的宽度(过渡的目标值/最终值)
// 通过横轴的比例尺的方法 x.bandwidth() 获取 band 的宽度(不包含间隙 padding)
.attr("width", x.bandwidth());
}
此外该例子中用于生成数据的方法也值得参考,可以产生平滑变化的随机数
/**
*
* 生成(随机)数据
*
*/
// 该函数可以产生 m 个随机数(伪随机),它们是平滑变化的非负数
// 受到 Lee Byron 用于生成的测试数据的方法的启发,参考 http://leebyron.com/streamgraph/
function bumps(m) {
const values = [];
// 先在 [0.1, 0.2) 范围内,生成 m 个符合均匀分布的随机数
for (let i = 0; i < m; ++i) {
// 调用 JS 原生方法 Math.random() 可生成 [0, 1) 之间的随机数(符合均匀分布 uniform distribution)
values[i] = 0.1 + 0.1 * Math.random();
}
// 对上面生成的 m 个未知数进行 5 次随机跳跃 random bumps 处理
for (let j = 0; j < 5; ++j) {
const x = 1 / (0.1 + Math.random());
const y = 2 * Math.random() - 0.5;
const z = 10 / (0.1 + Math.random());
for (let i = 0; i < m; i++) {
const w = (i / m - y) * z;
values[i] += x * Math.exp(-w * w);
}
}
// 确保所有随机数都是非负数
for (let i = 0; i < m; ++i) {
// 遍历 m 个随机数,对它们的取值进行约束 Math.max(0, values[i])
values[i] = Math.max(0, values[i]);
}
return values;
}
在该例子中还有值得关注的一点,是对于颜色比例尺所选择的配色方案的考量,一般而言有两种配色方案可供考量:
- 离散型的配色方案
- 连续型的配色方案
在这个例子中不像其他堆叠条形的官方样例那样使用 d3.scaleOrdinal() 排序比例尺构建颜色比例尺,这是为了兼容更多的场景 ❓
因为排序比例尺一般与离散型的配色方案一起使用,但是这类配色方案的可选颜色值的数量是有限的。因为实际上这类配色方案是预设了一些的颜色值,以数组的形式来存储,一般针对用于数据已知的场景,可以确保可选的颜色值与类别数量一一匹配
但是在该例子中,数据的系列/类别是变量 n 是可变更的,所以选择连续型的配色方案更合适,并与 d3.scaleSequential 顺序比例尺配合使用。连续型的配色方案实际上是一个 interpolator 插值器(函数),通过传入参数再计算得到相应的颜色值,理论上可以从连续的色谱中「采样」得到无数的颜色值,例如在该例子种使用 d3.interpolateBlues 配色方案
提示
连续型配色方案可以按需从中进行「采用」,作为离散型配色方案使用,例如 d3.schemeBlues[9] 可以从连续型配色方案中提取出 9 种颜色
以下是颜色比例尺的相关代码
// 设置颜色比例尺
// 为不同系列设置不同的配色
// 使用 d3.scaleSequential 构建一个顺序比例尺 Sequential Scales 将连续型的定义域映射到连续型的值域
// 它和线性比例尺类似,但是它的配置方式并不相同,通常会指定一个插值器 interpolator 作为值域
// 具体参考官方文档 https://d3js.org/d3-scale/sequential
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#顺序比例尺-sequential-scales
// 以下创建顺序比例尺时,同时设置了插值器(值域)
// 它是一个 D3 的内置配色方案 d3.interpolateBlues 可以从连续型的蓝色中进行颜色「采样」
// 具体可以查看 https://d3js.org/d3-scale-chromatic/sequential#interpolateBlues
const color = d3.scaleSequential(d3.interpolateBlues)
// 设置定义域范围
// ⚠️ 这里并不是直接将 [0, n] (n 为系列的数量)设置为颜色比例尺的定义域
// 因为 d3.interpolateBlues 插值器所对应的色谱,开始于**接近白色的浅蓝色**
// 如果将颜色比例尺的定义域范围设置 [0, n] 即与系列/类别的编码一致
// 那么堆叠条形图的第一层(或分组条形图的每个组中的第一条条带)的颜色就会映射到色谱的最开始的颜色(浅蓝色)
// 会影响可视性
// 所以这里在设置颜色比例尺的定义域范围时,将 [0, n] 扩展为 [-0.5 * n, 1.5 * n]
// 相当于「采样」色谱靠近中间的颜色,则开始的系列所对应的颜色会更易于阅读
.domain([-0.5 * n, 1.5 * n]);
变体
直方图
直方图是将连续型的数据进行分组,归档到(离散的)不同组别中,以实现对一维数据分布的可视化。
直方图从外观而言,和条形图十分类似,但是它的所用和适用范围都有一些明显的差别,因此在 D3.js 中制作直方图所用的方法和模块也有所不同:
- 绘制普通的柱状图时所使用的数据点,它们一般都会有明显的(离散型的)区分标记,例如基于数据点中的某个属性,可以直接将这些数据点进行分组,再分别绘制为一个条带
- 而绘制直方图时所使用的数据点是连续型的,而且没有直观的区分标记,所以需要先「手动」基于数据的范围进行分组,然后将这些数据点归档到(离散的)不同组别中,最后再分别绘制为一个条带
在制作直方图时,与普通的条形图最主要的不同是,在第一步就是需要对数据范围进行分组/划分,得到一系列范围更小、非重叠的区间/级别/档次,它们称为 bin(箱子),因此这个步骤也称为 binning data 分组,就相当于将数据点装到不同的箱子中
该步骤所使用核心方法 d3-array 模块的 d3.bin() 调用它会创建一个分档器,即 bin 生成器(以下称为 bin)
分档器是一个函数,它被调用时 bin(data) 接收数据集作为入参,然后就会对样本数据继续分组。
返回一个数组,数组的每个元素就是一个 bin(区间),它包含了属于该档次的样本数据,因此元素也是一个数组,所以该元素(内嵌的数组)的长度就是该档次的样本的数量。
另外对于每个 bin 对象还有两个特殊的属性(数组是对象特殊的对象,可以添加属性):
x0表示该 bin 的下限(包含)x1表示该 bin 的上限(不包含,除非它是最后一个区间,则包含上限)
以下是一个示例
const data = [
17.183683395385742,
16.896495819091797,
7.694344997406006,
7.116129398345947,
5.88179349899292,
14.245878219604492,
16.827415466308594,
17.579294204711914,
17.654016494750977,
1.1367906332015991,
];
const bin = d3.bin();
const buckets = bin(values1);
// [
// [1.1367906332015991, x0: 0, x1: 5],
// [7.694344997406006, 7.116129398345947, 5.88179349899292, x0: 5, x1: 10],
// [14.245878219604492, x0: 10, x1: 15],
// [17.183683395385742, 16.896495819091797, 16.827415466308594, 17.579294204711914, 17.654016494750977, x0: 15, x1: 20],
// ]
参考
关于数据分组 binning data 更多介绍可以参考 d3-array 模块的相关部分或 官方文档,或者另一篇笔记
堆叠条形图
堆叠柱状图和普通的柱状图外观上很类似,但实际上堆叠柱状图的条带是由多个数据点构成的,所以对应的数据格式,以及可视化时所使用的 D3 模块也会不同。
参考
- 解读的官方样例为 Stacked Bar Chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中主要不同是需要使用 d3-shape 模块 里面的关于 堆叠 stack 的一些方法
使用方法 d3.stack() 创建一个堆叠生成器(以下称为 stack)对数据进行转换,便于后续绘制堆叠图
提示
关于堆叠生成器的详细介绍可以查看这一篇笔记
例如对于如下数据
// 原始数据样例
// 数组每个元素都是一条数据记录,它包含了多个系列的数据(不同类型的水果在当月的销量)
const data = [
{month: new Date(2015, 0, 1), apples: 3840, bananas: 1920},
{month: new Date(2015, 1, 1), apples: 1600, bananas: 1440},
];
// 创建一个堆叠生成器
const stack = d3.stack()
.keys(["apples", "bananas"]) // 设定系列名称
// 对原数据进行转换
const series = stack(data);
console.log(series)
经过堆叠生成器的转换,可以得到一个嵌套数组,其中每一个元素(嵌套的数组)就是一个系列
// 返回的结果,转换后得到各系列的数据
[
// 每一个系列的数据都独立「抽取」出来组成一个数组
// apple 系列数据
[
// 每个元素都是 apple 的月销量数据点
// 前两个数值类似于面积图中的下边界线和上边界线
// data 对象保留了转换前该数据点对应的原始数据来源
[0, 3840, data: {month: 2014-12-31T16:00Z, apples: 3840, bananas: 1920}], // 12 月销量
[0, 1600, data: {month: 2015-01-31T16:00Z, apples: 1600, bananas: 1440}], // 1 月销量
key: "apples", // 该系列对应的 key(名称)
index: 0 // 该系列在 series 中的顺序(即对应于堆叠条形图中该系列叠放的次序)
],
// bananas 系列数据
[
[3840, 5760, data: {month: 2014-12-31T16:00Z, apples: 3840, bananas: 1920}],
[1600, 3040, data: {month: 2015-01-31T16:00Z, apples: 1600, bananas: 1440}],
key: "bananas",
index: 1
]
]
系列
这里所说的系列对应于堆叠条形图里的一个横跨多个条带的水平堆叠层,一般用一种颜色来表示一个堆叠层
可以从两个维度看待堆叠条形图,从上下垂直方向上看,由多个相互独立的条带构成;而从左右水平方向看,由多个相互堆叠的小矩形
而条形图的一个条带就是有多个堆叠层「垒起来」而形成的
由于堆叠条形图所对应的数据结构是嵌套数组,所以在数据绑定时也会相应地需要进行「二次绑定」,以下是与数据绑定相关的核心代码
// 绘制的步骤与一般的条形图会有所不同
// 因为普通的条形图每一个条带都只是有一个矩形构成
// 而堆叠条形图的每一个条带是由多个小的矩形依次堆叠而成的
// 相应地,它们所绑定/对应的数据结构也不同
// 普通的条形图所绑定的数据是一个数组,页面上每一个条带对应数组中的一个元素
// 而堆叠条形图所绑定的数据是一个嵌套数组,页面上每一个堆叠层分别对应于数组的一个元素(一个系列数据,它也是一个数组),而同一堆叠层的不同小矩形则分别对应于嵌套数组中的一个元素
// 所以需要在绘制堆叠条形图时需要进行数据「二次绑定」
svg.append("g")
.selectAll() // 返回一个选择集,其中虚拟/占位元素是 <g> 它们作为各系列的容器
.data(series) // 绑定数据,每个容器 <g> 对应一个系列数据
.join("g")
// 设置颜色,不同系列/堆叠层对应不同的颜色
// 💡 关于颜色比例尺的介绍可以查看下文
.attr("fill", d => color(d.key))
// 基于原有的选择集进行「次级选择」,选择集会发生改变
// 详细介绍可以查看这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-binding#次级选择
.selectAll("rect") // 使用 <rect> 元素为每一堆叠层绘制出一系列的小矩形
// 返回的选择集是由多个分组(各个 <g> 容器中)的虚拟/占位 <rect> 元素构成的
// ⚠️ 使用 select.selectAll() 所创建的新选择集会有多个分组
// 由于新的选择集会创建多个分组,那么原来所绑定数据与(选择集中的)元素的对照关系会发生改变
// 从原来的一对一关系,变成了一对多关系,所以新的选择集中的元素**不会**自动「传递/继承」父节点所绑定的数据
// 所以如果要将原来选择集中所绑定的数据继续「传递」下去,就需要手动调用 selection.data() 方法,以显式声明要继续传递数据
// 在这种场景下,该方法的入参应该是一个返回数组的**函数**
// 每一个分组都会调用该方法,并依次传入三个参数:
// * 当前所遍历的分组的父节点所绑定的数据 datum
// * 当前所遍历的分组的索引 index
// * 选择集的所有父节点 parent nodes
// 详细介绍可以查看这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-binding#绑定数据
// 所以入参 D 是一个堆叠系列的数据(即 series 的一个嵌套数组)
// 每个元素是一个二元数组,第一个元素是堆叠小矩阵的下边界;第二个元素是上边界;另外数组对象还具有一个属性 data 它包含原始数据(它也是一个二元数组,其中第一个元素 data[0] 就是所属的州的名称)
// 这个函数的作用是为每个元素(数组对象)添加一个 key 属性(所属的系列名称/年龄分组),然后返回本身
.data(D => D.map(d => (d.key = D.key, d)))
.join("rect") // 将元素绘制到页面上
// 为每个小矩形分别设置左上角 (x, y) 及其 width 和 height 来确定其定位和形状
// 每个矩形的左上角横轴定位 x 由它所属的州的名称决定
// 可以通过所绑定数据的属性 d.data[0] 来获取
// 使用横坐标轴的比例尺(带状比例尺)进行映射,求出具体的横轴坐标值
.attr("x", d => x(d.data.name))
// 每个矩形的左上角纵轴定位 y 由它的堆叠上边界决定
// 可以通过它所绑定的数据(一个数组)的第二个元素 d[1] 来获取
// 使用纵坐标轴的比例尺(线性比例尺)进行映射,求出具体的纵轴坐标值
.attr("y", d => y(d[1]))
// 每个矩形的高度
// 由所绑定的数组的两个元素(上边界和下边界)之间的差值所决定
// ⚠️ 注意这里的差值是 y(d[0]) - y(d[1]) 因为 svg 的坐标体系中向下是正方向
// 所以下边界 d[0] 所对应的纵坐标值 y(d[0]) 会更大,减去 y(d[1]) 的值求出的差值才是高 度
.attr("height", d => y(d[0]) - y(d[1]))
// 每个矩形的宽度
// 通过横轴的比例尺的方法 x.bandwidth() 获取 band 的宽度(不包含间隙 padding)
.attr("width", x.bandwidth())
在所参考的官方样例中,会对原始数据格式进行复杂的转换,将扁平结构(数组)变成层级结构(映射),以便于基于 key 获取 value
而在复现时则采用不同的方式,并没有改变数组这种扁平结构,而是根据实际需要为数组的每个元素添加一些额外的属性
/**
*
* 对数据进行转换
*
*/
// 求出各州的总人口,并作为 total 属性添加到 data 各个元素(对象)上
// 在对条形图各条带进行排序,以及设置纵坐标轴的定义域时,都需要使用该值
// 💡 其实后面所求出的系列数据 series,该数组的最后一个系列中(也是一个数组),各元素的堆叠顶部值 stackTop 就是各州的总人口
data.forEach(element => {
element.total = d3.sum(Object.values(element))
});
另外为了便于区分不同系列(由于不同系列的小矩形会「垒在一起」),需要设置颜色比例尺,将不同系列映射到不同的颜色上,即不同的堆叠层的矩形会填充上不同的颜色,以下关于颜色比例尺的核心代码
// 设置颜色比例尺
// 为不同系列设置不同的配色
// 使用 d3.scaleOrdinal() 排序比例尺 Ordinal Scales 将离散型的定义域映射到离散型值域
// 具体参考官方文档 https://d3js.org/d3-scale/ordinal 或 https://github.com/d3/d3-scale/tree/main#scaleOrdinal
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#排序比例尺-ordinal-scales
const color = d3.scaleOrdinal()
// 设置定义域范围
// 各系列的名称,即 9 个年龄段
.domain(series.map(d => d.key))
// 设置值域范围
// 使用 D3 内置的一种配色方案 d3.schemeSpectral
// 它是一个数组,包含一些预设的配色方案
// 通过 d3.schemeSpectral[k] 的形式可以快速获取一个数组,其中包含 k 个元素,每个元素都是一个表示颜色的字符串
// 其中 k 需要是 3~11 (包含)之间的数值
// 具体参考官方文档 https://d3js.org/d3-scale-chromatic/diverging#schemeSpectral 或 https://github.com/d3/d3-scale-chromatic/tree/main#schemeSpectral
// 这里根据系列的数量生成相应数量的不同颜色值
.range(d3.schemeSpectral[series.length])
// 设置默认颜色
// 当使用颜色比例尺时 color(value) 传入的参数不在定义域范围中,默认返回的颜色值
.unknown("#ccc");
堆叠条形图示例
参考
- 解读的官方样例为 Revenue by Music Format, 1973–2018
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
核心代码和前一小节所述的一样
有一个小点值得学习,在可视中表示较大数值时可以采用缩写的方式
在 JavaScript 中可以通过在数字后面附加字母 e 并指定零的个数来缩短数字
let billion = 1e9; // 10 亿,字面意思:数字 1 后面跟 9 个 0
alert( 7.3e9 ); // 73 亿(与 7300000000 和 7_300_000_000 相同)
在该示例中为每个堆叠小矩形设置 Tooltip 提示框内容时,就根据数值的大小而采用不同等级的缩写形式
对数值的格式化的相关代码如下
// 用于格式化 tooltip 文本内容
const formatRevenue = x => (+(x / 1e9).toFixed(2) >= 1)
? `${(x / 1e9).toFixed(2)}B` // 如果数值大于 10 亿,则以 10 亿作为基数,修约到小数点后 2 位,并添加 B 后缀
: `${(x / 1e6).toFixed(0)}M` // 如果数值小于 10 亿,则以 100 万作为基数,修约到个位,并添加 M 后缀
横向堆叠条形图
参考
- 解读的官方样例为 Stacked Bar Chart, Horizontal
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其实水平堆叠条形图与垂直堆叠条形图相比,在代码上大部分都是相同的,相当于只是将横坐标轴和纵坐标轴相互调换
其中有几点不同值得关注和学习参考:
- 在垂直堆叠条形图中,条带分布是从左往右的,每个条带的宽度与页面宽度相关;而在水平堆叠条形图中,条带分布是从上往下的,每个条带的宽度是手动设定的(相同值)
这是由于在桌面端的浏览器中,水平滚动的操作比较麻烦,所以 svg 的横向宽度一般不会超过页面的宽度,以避免产生横向滚动,所以条带横向分布时,每个条带的宽度就是由页面的宽度所决定(通过横坐标轴的比例尺算出条带的带宽)。
而在桌面端的浏览器中,垂直滚动很方便,所以这里可以手动设置条带的宽度,再计算出 svg 的高度,比页面/屏幕的高度更大也无所谓,并不需要将图表的高度限制在一页中。
所以在水平堆叠条形图中,svg 的高度是基于条形图中条带的数量和宽度,通过计算来求出,相关的核心代码如下js// 这里 series[0].length 所获得的是条带的数量(对应于 52 个州),每个条带的宽度(包含间隔)是 25px // 再加上 marginTop 和 marginBottom 上下的留白,总长作为 svg 的高度 const height = series[0].length * 25 + marginTop + marginBottom; - 在水平堆叠条形图中,通过设置每个小矩形的左上角
(x, y)来定位,其中x(横轴定位)由它的堆叠下边界决定,可以通过它所绑定的数据(一个数组)的第一个元素d[0]来获取,再使用横坐标轴的比例尺(线性比例尺)进行映射,求出具体的横轴坐标值
而对于垂直堆叠条形图,每个小矩形的左上角(x, y)中的y(纵轴定位)则是由它的堆叠上边界决定,可以通过它所绑定的数据(一个数组)的第二个元素d[1]来获取,再使用纵坐标轴的比例尺(线性比例尺)进行映射,求出具体的纵轴坐标值
发散型的堆叠条形图
参考
- 解读的官方样例为 Diverging stacked bar chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其实发散型的堆叠条形图与垂直堆叠条形图很类似,在绘制步骤及相应的代码上大部分都是相同的,只是采用了不同的堆叠基线函数 stack.offset(d3.stackOffsetDiverging) 以允许正值和负值分别进行堆叠,正值会在零之上进行堆叠,负值会在零之下堆叠
另外一点值得学习的是对纵坐标轴采用一些特别的设计,以便坐标轴标识和图表更搭配。
以上样例所采用的纵坐标轴是刻度值朝左的 d3.axisLeft(y),本来应该通过设置 CSS 的 transform 属性将坐标轴整合移到 svg 的最左侧的,但是由于它是一个沿水平方向左右发散的堆叠条形图,所以纵坐标轴的轴线应该在 svg 的中间(即横坐标轴的零点所在的位置),而如果将刻度仍留在最左边则会显得很与图表格格不入,所以官方样例巧妙地将每个刻度(包括刻度线和刻度值)分别移到不同的距离,定位到相应条带的最左端(紧挨着条带),将坐标轴的刻度变成一个个条带的标识/注释 annotation
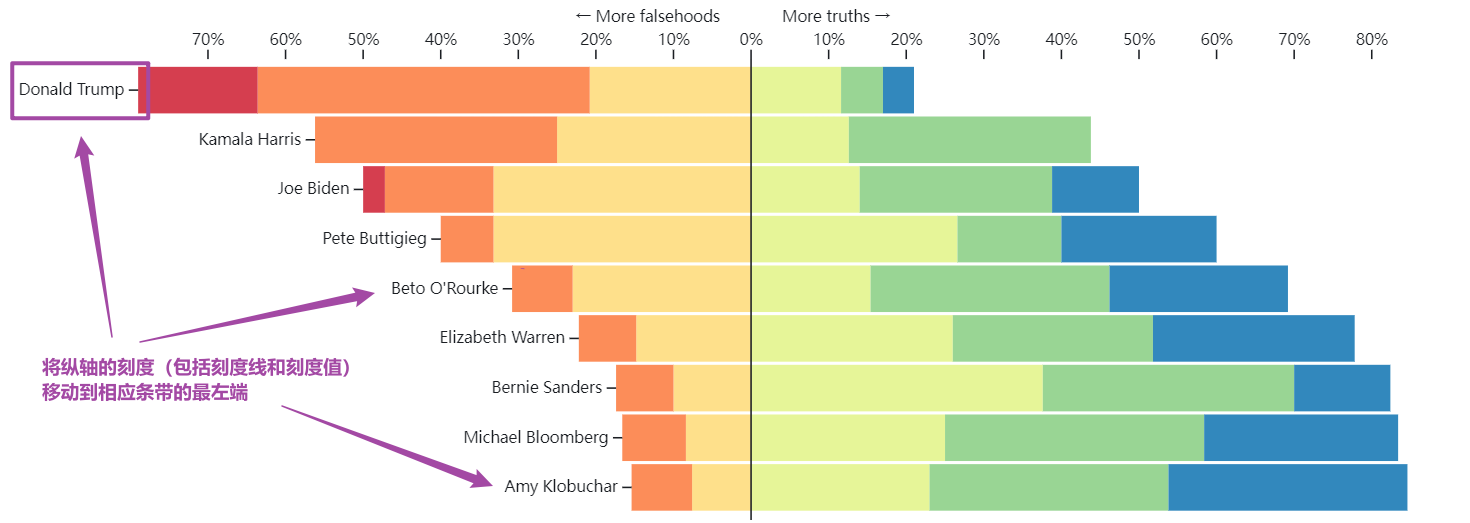
相关的代码如下
// 绘制纵坐标轴
svg.append("g")
// 💡 纵轴是一个刻度值朝左的坐标轴
.call(d3.axisLeft(y).tickSizeOuter(0))
// 设置坐标轴刻度线和刻度值的定位
// 通过 class 类名 ".tick" 选中所有的刻度(容器,其中分别包括两个元素,<line> 是刻度线,<text> 是刻度值)
// 绑定数据 bias
// 它一个嵌套数组,即每一个元素都是一个数组,这些内嵌的数组都有两个元素
// 可以通过解构 [name, min] 获取到总统候选人的名称 name,及其对应的负面类别的数据的总和 min
// 然后通过 x(min) 可以得到该总统候选人所对应的条带的左端的横坐标轴的值
// 通过 y(name) 可以得到该总统候选人所对应的条带的纵坐标轴的值
// 那么 y(name) + y.bandwidth() / 2 就是条带的中间位置(由于 svg 的正方向是向右和向下的)
// 然后通过设置 CSS 的 transform 属性基于以上的计算值,将刻度移到相应的(条带左端)位置
.call(g => g.selectAll(".tick").data(bias).attr("transform", ([name, min]) => `translate(${x(min)},${y(name) + y.bandwidth() / 2})`))
// 而纵坐标轴的轴线(含有 class 类名 ".domain" 从 svg 的左侧移动到横坐标轴的零点位置 x(0)
.call(g => g.select(".domain").attr("transform", `translate(${x(0)},0)`));
拓展阅读
发散型的堆叠条形图可以在一个图中展示正负值,但是这会削弱「堆叠」的作用,即比较局部堆叠的数据与总体数据的关系,特别是在存在「中性」数据的情况下
在堆叠一个条带时,一般会将「中性」的矩形置于零刻度线的两侧,即一半的「中性」数据看作属于正值,一半属于负值,但是这种简单的二元划分处理在实际的项目中可能造成误导
另外由于「中性」数据的存在,采用以上方式堆叠,会让正负值的矩形的基线偏移,使得它们的堆叠并不是从零开始,那么要进行条带之间的比较就会很困难
Rost & Aisch 写了一篇文章 《The case against diverging stacked bars》 祂们并不推荐使用该类型的堆叠图,可以详细阅读了解其中的原因,以便找到合适的使用场景。
标准化的堆叠条形图
参考
- 解读的官方样例为 Stacked Bar Chart, Normalized
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
标准化的堆叠条形图与水平/垂直堆叠条形图相比,在代码上大部分都是相同的,相当于只是将基线函数更改为 d3.stackOffsetExpand 相关的代码如下
// 通过堆叠生成器对数据进行转换,便于后续绘制堆叠图
// 返回一个数组,每一个元素都是一个系列(条形图中每个条带就是由多个系列堆叠而成的)
// 💡 另外 D3 为每一个系列都设置了一个属性 key 其值是系列名称
// 而每一个元素(系列)也是一个数组,其中每个元素是该系列在条形图的每个条带中的相应值,例如在本示例中,有 52 个州,所以每个系列会有 52 个数据点
// 具体可以参考官方文档 https://d3js.org/d3-shape/stack 或 https://github.com/d3/d3-shape/blob/main/README.md
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#堆叠生成器-stacks
const series = d3.stack()
// 设置系列的名称(数组),即有哪几种年龄的分组
// 通过 data 的属性 columns 提取年龄段
// ⚠️ 注意只从第二个元素开始提取 data.columns.slice(1)
// 因为 csv 表格的第一列是各州的名称 name ,并不是年龄段的分组
// 可以提取到 9 个年龄段
.keys(data.columns.slice(1))
// 设置堆叠基线函数,这里采用 D3 所提供的一种默认基线函数 d3.stackOffsetExpand
// 对数据进行标准化(相当于把同一个条带中各系列的绝对数值转换为所占的百分比),基线是零,上边界线是 1
// 所以每个堆叠而成的条带长度都一致
// 具体可以参考官方文档 https://github.com/d3/d3-shape/blob/main/README.md#stackOffsetExpand
.offset(d3.stackOffsetExpand)
(data)
另外在该示例中,对于条带进行了排序,依据是第一个堆叠数据所占该条带总数据的比例大小,相关的代码如下
// 💡 设置纵坐标轴的比例尺,与**垂直堆叠条形图**的横坐标轴相对应
// 纵坐标轴的数据是条形图的各种分类,使用 d3.scaleBand 构建一个带状比例尺
// 使用 d3-scale 模块
// 具体参考官方文档 https://d3js.org/d3-scale/band 或 https://github.com/d3/d3-scale#scaleBand
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#带状比例尺-band-scales
const y = d3.scaleBand()
// 设置定义域范围(52 个州)
// 使用 d3.union(data.map(d => d.name)) 从原数据中提取出州的名称的并集,并返回一个数组
// 再使用 d3.sort() 对该数组的元素进行排序
// 排序依据是年龄段为 "<10" 的人口数量占该州总人口的比例
// 按照降序排列,即年龄小于 10 岁的人数较多的州排在前面
.domain(d3.sort(d3.union(data.map(d => d.name)), (stateA, stateB) => {
const stateAElem = data.find(element => element.name === stateA)
const stateBElem = data.find(element => element.name === stateB)
if (stateAElem && stateBElem) {
// 降序排列
return d3.descending(stateAElem["<10"] / stateAElem.total, stateBElem["<10"]/stateBElem.total)
} else {
return 0
}
}))
// 设置值域范围(所映射的可视元素)
// 这里的 height 高度是前面根据条形图的条带宽度和数量计算出来的
.range([marginTop, height - marginBottom])
.padding(0.08); // 并设置间隔占据(柱子)区间的比例
分组条形图
分组条形图可以用于展示具有子类的嵌套数据,可以将它看作是堆叠条形图的「平铺展开」形式,在视觉上而言每一个大类都包含一堆条带,而在一个大类的区间中的每个条带表示一个子类
参考
- 解读的官方样例为 Grouped bar chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
由于分组条形图的数据具有二级分类,所以相应地需要两个比例尺,例如对于以上示例的横坐标比例尺,由「宏观」和「微观」两个比例尺构成,相关的核心代码如下
// 设置横坐标轴的比例尺,它由「宏观」和「微观」两个比例尺构成
// 「宏观」比例尺用于将各组(整体)映射/定位到横坐标轴上
// 「微观」比例尺用于安排各组内的条带映射/定位到组内区间上
// fx 比例尺用于将 6 个州映射到横坐标轴上
// 由于数据是不同的州(不同的分类),使用 d3.scaleBand 构建一个带状比例尺
// 使用 d3-scale 模块
// 具体参考官方文档 https://d3js.org/d3-scale/band 或 https://github.com/d3/d3-scale#scaleBand
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#带状比例尺-band-scales
const fx = d3.scaleBand()
// 设置定义域范围(6 个州,从 data 数据点的属性 d.state 所构成的集合种提取出所有的州)
.domain(new Set(data.map(d => d.state)))
// 设置值域范围
// svg 元素的宽度(减去留白区域)
// 使用 scale.rangeRound() 方法,可以进行修约,以便实现整数(6 个州)映射到整数(像素)
.rangeRound([marginLeft, width - marginRight])
.paddingInner(0.1); // 并设置间隔占据(每个州)区间的比例
// x 比例尺用于将条带映射到组内区间上
// 由于数据是的不同的年龄段(不同的分类),所以同样使用 d3.scaleBand 构建一个带状比例尺
const x = d3.scaleBand()
// 设置定义域范围(不同的年龄段的名称)
.domain(ages)
// 设置值域范围
// 就是每个州的区间宽度,所以值域的上边界是前面带状比例尺 fx 的带宽
.rangeRound([0, fx.bandwidth()])
.padding(0.05); // 并设置间隔占据(每个条带)的比例