D3 面积图
静态图
参考
- 解读的官方样例为 Area chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
官方样例的构建流程概述:
- 读取数据
- 构建比例尺
- 绘制面积图的容器(边框和坐标轴)
- 创建一个面积生成器
- 绘制面积图内的面积形状
在该例子中需要学习留意的一点是,由于数据集是 Apple 股票的(从 2007-04-23 至 2012-05-01)每日收盘价,所以(横坐标轴)需要使用时间比例尺。
D3 提供了两种方法构建时间比例尺,两者所创建的时间比例尺具有相同的方法,但是所采用的时间表示方式不同:
d3.scaleTime(domain, range)所创建的时间比例尺所采用的是地方时 Local Time,如果用户的浏览器所采用的时区不同,则显示不同的时间d3.scaleUtc(domain, range)所创建的时间比例尺采用协调世界时 Universal Time Coordinated,简称为 UTC,所以即使处于不同时区的用户也会显示同样的时间
在该例子中使用 d3.scaleUtc() 构建一个时间比例尺
提示
关于协调世界时和地方时的具体介绍可以查看这一篇笔记
提示
可以与另一种可视化形式 line chart 折线图相对比
数据缺失的面积图
参考
- 解读的官方样例为 Area chart with missing data
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
该示例使用与前一个例子一样的数据源,但是进行一些修改,以手动模拟数据缺失的情况
关于数据处理的相关代码如下
// 💡 遍历 aapl 数组的每一个元素,修改数据点(对象)的属性 close 的值,以手动模拟数据缺失的情况
// 当数据点所对应的日期的月份小于三月份(包含),则收盘价改为 NaN;否则就采用原始值
// 📢 由于 JS 的日期中,月份是按 0 开始算起的,所以 1、2、3 月份是满足以下的判断条件 d.date.getUTCMonth() < 3
const aaplMissing = aapl.map(d => ({ ...d, close: d.date.getUTCMonth() < 3 ? NaN : d.close })) // simulate gaps
调用面积生成器方法 area.defined(callback) 可以设置数据完整性检验。所设置的回调函数 callback 会在调用面积生成器时,为数组中的每一个元素都执行一次,返回布尔值,以判断该元素的数据是否完整。
回调函数 callback函数传入三个参数:
- 当前的元素
d - 该元素在数组中的索引
i - 整个数组
data
当函数返回 true 时,面积生成器就会执行下一步(调用坐标读取函数),最后生成该元素相应的坐标数据;当函数返回 false 时,该元素就会就会跳过,当前面积就会截止,并在下一个有定义的元素再开始绘制,反映在图上就是一个个分离的面积区块
在该例子中通过判断值是否为 NaN 来判定该数据是否缺失,相关代码如下
const area = d3.area()
// 💡 调用面积生成器方法 area.defined() 设置数据完整性检验函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,返回布尔值,以判断该元素的数据是否完整
// 该函数传入三个入参,当前的元素 `d`,该元素在数组中的索引 `i`,整个数组 `data`
// 当函数返回 true 时,面积生成器就会执行下一步(调用坐标读取函数),最后生成该元素相应的坐标数据
// 当函数返回 false 时,该元素就会就会跳过,当前面积就会截止,并在下一个有定义的元素再开始绘制,反映在图上就是一个个分离的面积区块
// 具体可以参考官方文档 https://d3js.org/d3-shape/area#area_defined
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
// 这里通过判断数据点的属性 d.close(收盘价)是否为 NaN 来判定该数据是否缺失
.defined(d => !isNaN(d.close))
// 设置设置下边界线横坐标读取函数
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数
.y0(y(0))
// 设置上边界线的纵坐标的读取函数
.y1(d => y(d.close));
该示例实际上绘制了两种颜色的面积(灰色和蓝色),并进行覆盖叠加,最终的效果是在面积图缺口位置由灰色的区块填补,相关代码如下
// 💡 先绘制灰色的区域
svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 将面积的填充颜色设置为灰色
.attr("fill", "#ccc")
.attr("d", area(aaplMissing.filter(d => !isNaN(d.close))));
// 其实以上的操作绘制了一个完整的面积图,由于过滤掉缺失的数据点,所以可以绘制出了一个完整(无缺口)的面积图
// 由于 **线性插值法 linear interpolation** 是面积生成器在绘制边界线时所采用的默认方法,所以对于那些缺失数据的位置,通过连接左右存在的完整点,绘制出的「模拟」线段来填补边界线的缺口
// 再绘制蓝色的面积区块(完整性的数据点)
svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 将面积的填充颜色设置为蓝色
.attr("fill", "steelblue")
.attr("d", area(aaplMissing));
// 由于含有缺失数据,所以绘制出含有缺口的面积图
// 蓝色面积图覆盖(重叠)在前面所绘制的灰色面积图上,所以最终的效果是在缺口位置由灰色的区块填补
交互性
可缩放的面积图
参考
- 解读的官方样例为 Zoomable area chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
关于缩放交互的核心代码如下
/**
*
* 缩放交互
*
*/
// 缩放事件的回调函数
// 当缩放时,需要更新横坐标轴比例尺,并重绘面积图
// 其中参数 event 是 D3 的缩放事件对象
// 该缩放事件对象的属性 transform 包含当前的缩放变换值,还提供一些方法用于操作缩放
function zoomed(event) {
// 调用方法 transform.rescaleX(x) 更新横轴轴比例尺
// 返回一个定义域经过缩放变换的比例尺(这样映射关系就会相应的改变,会考虑上缩放变换对象 transform 的缩放比例)
// 💡 关于方法 transform.rescaleX(x) 的介绍可以参考这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-interact#缩放变换对象的方法
const xz = event.transform.rescaleX(x);
// 调用函数 area(data, xz) 返回的结果是字符串,更新变量 path(它是一个选择集,里面包含一个 <path> 元素)的属性 d
// 其中参数 xz 是更新后的的横坐标比例尺
path.attr("d", area(data, xz));
// 使用新的比例尺重新绘制横坐标轴
gx.call(xAxis, xz);
}
// 创建缩放器
const zoom = d3.zoom()
// 约束缩放比例的范围,默认值是 [0, ∞]
// 入参是一个数组 [1, 32] 表示最小的缩放比例是 1 倍,最大的缩放比例是 8 倍
.scaleExtent([1, 32])
// 缩放器除了可以缩放,还可以进行平移,以下两个方法分别设置与平移相关参数
// 设置视图范围 viewport extent
// 入参是一个嵌套数组,第一个元素是面积图的矩形区域的左上角,第二个元素是右下角
// 如果缩放器绑定的是 svg,则视图范围 viewport extent 默认是 viewBox
// 这里「校正」为用于绘制面积图的区域大小(不包含 margin 的区域)
.extent([[marginLeft, 0], [width - marginRight, height]])
// 约束平移的范围 translate extent,默认值是 [[-∞, -∞], [+∞, +∞]]
// 这里设置平移的范围:最左侧为面积图的左边;最右侧为面积图的右边(最上方和最下方的范围虽然是无限的,但是这里只会进行水平缩放,所以也只可能进行水平移动,并不能进行上下移动)
// 所以即使放大后,画布也只能在面积图的最左边和最右边之间来回移动
.translateExtent([[marginLeft, -Infinity], [width - marginRight, Infinity]])
.on("zoom", zoomed); // 缩放事件的回调函数
// 🔎 以上提及的视图范围 viewport extent 和平移范围 translate extent 这两个概念,具体可以查看 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-interact
// 为 svg 添加缩放事件监听器
svg.call(zoom)
其中值得学习的一个巧思是:面积图初始缩放状态是放大的,而且(从无缩放状态)切换到初始缩放状态时设置了过渡动效,这样就有让首次浏览器该可视化图形的用户知道该面积图是支持缩放交互的。
设置过渡动效的相关代码如下
// 为 svg 添加缩放事件监听器
svg.call(zoom)
// 通过 selection.transition() 创建过渡管理器
// 💡 这样(从无缩放状态)切换到初始缩放状态时,就可以有过渡动效
.transition()
.duration(750) // 设置过渡持续时间
// 设置初始缩放状态
// 💡 transition.call(function[, arguments…]) 执行一次函数 function 它其实和 selection.call() 方法类似
// 💡 而且将过渡管理器作为第一个入参传递给 function,而其他传入的参数 arguments... 同样传给 function
// 💡 最后返回当前过渡管理器,这样是为了便于后续进行链式调用
// 具体参考官方文档 https://d3js.org/d3-transition/control-flow#transition_call
// 或这一篇文档 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-transition#过渡参数配置
// 使用方法 zoom.scaleTo(selection, k[, p]) 对选择集的元素进行缩放操作,并将缩放比例设置为 k
// 第三个参数 p 是构建平滑的缩放过渡的参照点,默认为视图的中点,该参考点在缩放过程中不会发生移动
// 这里将初始状态设置为放大 4 倍,过渡参考点是设置为横坐标轴上的一个点(日期 Date.UTC(2001, 8, 1) 所对应的位置),也是靠近中间的位置
.call(zoom.scaleTo, 4, [x(Date.UTC(2001, 8, 1)), 0]);
另外还有一个值得注意的设计细节:当面积图放大时,图形会「延伸」到纵轴后,阻碍纵轴的显示。所以需要为面积图的 <path> 元素设置属性 clip-path,引用一个预设的 <clipPath> 路径剪裁遮罩,对图形进行裁剪/约束,相关代码如下
// 创建一个 identifier 唯一标识符(字符串)
// 它会作为一些 <clipPath> 元素的 id 属性值(方便其他元素基于 id 来使用),以避免与其他元素发生冲突
// 💡 在参考的 Observable Notebook 使用了平台的标准库所提供的方法 DOM.uid(namespace) 创建一个唯一 ID 号
// 💡 具体参考官方文档 https://observablehq.com/documentation/misc/standard-library#dom-uid-name
// 💡 方法 DOM.uid() 的具体实现可参考源码 https://github.com/observablehq/stdlib/blob/main/src/dom/uid.js
// const clip = DOM.uid("clip");
// 这里使用硬编码(手动指定)id 值
const clipId = "clipId";
// 创建一个元素 <clipPath> (一般具有属性 id 以便被其他元素引用)路径剪裁遮罩,其作用充当一层剪贴蒙版,具体形状由其包含的元素决定
// 💡 它不会直接在页面渲染出图形,而是被其他元素(通过设置属性 clip-path)引用的方式来起作用,为其他元素自定义了视口
// 这里在 <clipPath> 内部添加了一个 <rect> 设置剪裁路径的形状,以约束面积图容器的可视区域
// 则放大面积图时,超出其容器的部分就不会显示(避免遮挡坐标轴)
svg.append("clipPath")
// 为 <clipPath> 设置属性 id
.attr("id", clipId)
// 在其中添加 <rect> 子元素,以设置剪切路径的形状
.append("rect")
// 设置矩形的定位和尺寸
.attr("x", marginLeft) // 设置该元素的左上角的横坐标值(距离 svg 左侧 marginLeft 个像素大小)
.attr("y", marginTop) // 设置该元素的左上角的纵坐标值(距离 svg 顶部 marginTop 个像素大小)
.attr("width", width - marginLeft - marginRight) // 设置宽度(采用 svg 的宽度,并减去左右留白区域)
.attr("height", height - marginTop - marginBottom); // 设置宽度(采用 svg 的高度,并减去上下留白区域)
// 将面积形状绘制到页面上
// 变量 path 是一个选择集,里面包含一个元素 <path>,它是绘制面积形状的元素
const path = svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 设置属性 clip-path 以采用前面预设的 <clipPath> 元素对图形进行裁剪/约束
.attr("clip-path", clipId)
.attr("fill", "steelblue") // 将面积的填充颜色设置为蓝色
// 调用函数 area(data, x) 返回的结果是字符串,作为 `<path>` 元素的属性 `d` 的值
.attr("d", area(data, x));
可平移的面积图
参考
- 解读的官方样例为 Pannable chart
- 对代码进行注释解读的 Notebook 是这个,完整代码可以查看 这里
该示例的大部分代码与普通的静态面积图一样,只是将面积图分成两部分,不可滚动的部分(纵坐标轴)使用 svg 绘制,其宽度与页面一样的;可滚动的部分(横坐标轴和面积形状)使用另一个 svg 绘制,其宽度更大,并使用 <div> 元素(作为容器)包裹该 svg,使得他可以水平滚动,相关代码如下
/**
*
* 创建容器
*
*/
// 创建一个 <div> 元素作为两个 <svg> 的容器:
// * 其中一个 svg 包含面积形状和横坐标轴(它进一步包裹在一个子容器 <div> 里,子容器可以在父元素里横向滚动,实现面积图的水平可滚动的效果)
// * 另一个 svg 包含纵坐标轴
// Create a div that holds two svg elements: one for the main chart and horizontal axis,
// which moves as the user scrolls the content; the other for the vertical axis (which
// doesn’t scroll).
const parent = d3
.select("#container")
.append("div");
/**
*
* 绘制坐标轴
*
*/
// 在父容器里创建一个 svg 用于绘制纵坐标轴
parent.append("svg")
.attr("width", width) // svg 宽度与页面宽度一致,所以该元素不会滚动
.attr("height", height)
.style("position", "absolute") // 采用 absolute 定位,然后通过属性 z-index 设置层叠顺序
// 通过设置 CSS 属性 pointer-events 为 "none" 使该 svg 元素无法成为鼠标事件的目标
// 即在该元素上的鼠标操作会穿透该元素,作用于其下方的元素,以便可以在纵坐标轴出也可以操作(左右平移)面积图
.style("pointer-events", "none")
.style("z-index", 1) // 该 svg 元素叠于另一个 svg 元素的上层
.append("g") // 添加一个 <g> 元素作为纵坐标轴的容器
// 通过设置 CSS 的 transform 属性将纵向坐标轴容器「移动」到左侧
.attr("transform", `translate(${marginLeft},0)`)
// 纵轴是一个刻度值朝左的坐标轴
// 通过 axis.ticks(count) 设置刻度数量的参考值(避免刻度过多导致刻度值重叠而影响图表的可读性)
.call(d3.axisLeft(y).ticks(6))
// 删掉上一步所生成的坐标轴的轴线(它含有 domain 类名)
.call(g => g.select(".domain").remove())
// 为纵坐标轴添加标注信息
// 选中最后一个刻度值,即 <text> 元素,并进行复制
.call(g => g.select(".tick:last-of-type text").clone()
.attr("x", 3) // 设置元素的偏移量
.attr("text-anchor", "start") // 设置文字的对齐方式
.attr("font-weight", "bold") // 设置字体粗细
.text("$ Close")); // 设置文本内容
// 创建一个可滚动的 <div> 元素作为子容器,包含面积形状和横坐标轴
// Create a scrolling div containing the area shape and the horizontal axis.
const scrollBody = parent.append("div")
// 通过设置 CSS 的 overflow-x 属性为 scroll 允许该元素横向滚动
.style("overflow-x", "scroll")
// 通过设置 CSS 的 -webkit-overflow-scrolling 属性控制元素在移动设备上是否基于动量滚动
// 将该属性值设置为 touch 使用基于动量的滚动,即手指从触摸屏上抬起,滚动会继续一小段时间
// 具体参考相关文档 https://developer.apple.com/library/archive/documentation/AppleApplications/Reference/SafariCSSRef/Articles/StandardCSSProperties.html#//apple_ref/css/property/-webkit-overflow-scrolling 和 https://developer.mozilla.org/ko/docs/orphaned/Web/CSS/-webkit-overflow-scrolling
// ⚠️ 但这是非标准属性,不推荐在生产环境中使用,可能存在兼容问题
.style("-webkit-overflow-scrolling", "touch");
// 在子容器里创建一个 svg 用于绘制面积图和横坐标轴
const svg = scrollBody.append("svg")
.attr("width", totalWidth) // svg 宽度是页面宽度的 6 倍,所以该元素可以水平滚动
.attr("height", height)
.style("display", "block");
// 添加一个 <g> 元素作为横坐标轴的容器
svg.append("g")
// 通过设置 CSS 的 transform 属性将横坐标轴容器「移动」到底部
.attr("transform", `translate(0,${height - marginBottom})`)
// 横轴是一个刻度值朝下的坐标轴
.call(d3.axisBottom(x)
// 通过 axis.ticks(interval) 显式地设置坐标轴刻度应该如何生成(相隔多远生成一个刻度)
// 基于 D3 内置的边距计算器 d3.utcMonth(以一个以月为间距的 interval),使用方法 interval.every(step) 对其进行定制
// 这里 d3.utcMonth.every(1200 / width) 表示基于页面的宽度 width 调整采样的步长(原来的每个月进行采样生成横坐标轴的刻度),如果页面宽度 width 较小时 1200/width 就可能大于 1,则表示不是每个月采样,即可能间隔多个月才生成一条刻度线
// 💡 以上方法可以更细致地控制刻度线的生成方式,也可以使用 axis.ticks(count) 的形式设置刻度数量的参考值(但是可能无法更好地适应页面的宽度)
.ticks(d3.utcMonth.every(1200 / width))
// 而且将坐标轴的外侧刻度 tickSizeOuter 长度设置为 0(即取消坐标轴首尾两端的刻度)
.tickSizeOuter(0));
/**
*
* 绘制面积图内的面积形状
*
*/
// 使用 d3.area() 创建一个面积生成器
// 面积生成器会基于给定的数据生成面积形状
// 调用面积生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/area
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
const area = d3.area()
// 设置两点之间的曲线插值器,这里使用 D3 所提供的一种内置曲线插值器 d3.curveStep
// 该插值效果是在两个数据点之间,生成阶梯形状的线段(作为面积图的边界)
// 具体效果参考 https://d3js.org/d3-shape/curve#curveStep
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,以返回该数据所对应的横坐标
// 这里基于每个数据点的日期(时间)d.date 并采用比例尺 x 进行映射,计算出相应的横坐标
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数
// 这里的面积图的下边界线是横坐标轴,所以它的 y 值始终是 0,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y0(y(0))
// 设置上边界线的纵坐标的读取函数
.y1(d => y(d.close));
// 将面积形状绘制到页面上
svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 绑定数据
.datum(data)
// 将面积的填充颜色设置为蓝色
.attr("fill", "steelblue")
// 由于面积生成器并没有调用方法 area.context(parentDOM) 设置画布上下文
// 所以调用面积生成器 area 返回的结果是字符串
// 该值作为 `<path>` 元素的属性 `d` 的值
.attr("d", area);
// 使用 element.scrollBy(x-coord) 方法设置子容器滚动的初始值
// 面积图的初始状态是滚动到最右侧
// Initialize the scroll offset after yielding the chart to the DOM.
scrollBody.node().scrollBy(totalWidth, 0);
提示
其实前一个示例可缩放的面积图在放大后也是支持水平平移的,但是两者的绘制方式是不同的:
- 使用
d3.zoom实现的可缩放平移的面积图,需要响应用户的操作(鼠标事件)不断更新视图,即需要不断重绘视图才可以实现水平滚动,对于数据量较大时可能出现性能问题 - 而这个示例是并不需要重绘 svg 画布,只需要横向滚动就可以查看到 svg 的不同区域。但是这种方式也有不足,即预渲染出的 svg 尺寸是固定的,绘制完成后用户就无法进一步再放大了
刷选
参考
- 解读的官方样例为 Focus + Context
- 对代码进行注释解读的 Notebook 是这个,完整代码可以查看 这里
该例子由上下两个面积图组成,上面的是主图(显示部分数据,实现聚焦放大的效果),下面的是缩略图(显示完整的数据以提供上下文,并支持交互功能)
在缩略图里通过刷选构建选区,主图会相应地显示特定区域,实现放大的效果;在缩略图里拖拽灰色的矩形选框,主图会相应地聚焦到不同的区域
以下是实现刷选功能的核心代码
/**
*
* 缩略图
*
*/
// ...
// 刷选
// 创建一个 X 轴刷选器
const brush = d3.brushX()
// 设置可刷选区域,即缩略图的面积形状区域(将 svg 减去留白的区域)
// 刷选器会在该区域创建一个 <rect class="overlay" ...> 元素作为覆盖层,响应用户的刷选操作
.extent([[margin.left, 0.5], [width - margin.right, focusHeight - margin.bottom + 0.5]])
// 监听刷选过程中(如鼠标移动操作)所触发的事件,触发回调函数 brushed
.on("brush", brushed)
// 监听刷选结束时(如松开按键操作)所触发的事件,触发回调函数 brushended
.on("end", brushended);
// 设置默认的选区
// 使用 d3.utcYear 创建一个以年为间距的 interval,通过 interval.offset(date, step) 对入参的时间 date 进行偏移处理
// 关于时距器的介绍可以参考官方文档 https://d3js.org/d3-time#interval_offset
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-process#时间修约
// 这里入参的时间是 x.domain()[-1] 横坐标轴比例尺的定义域的上界(数据集中的最后一个日期,即 2012-05-01)
// 然后 step=-1 表示向前调整一年,即 2011-05-01,再使用比例尺 x 进行映射,计算出选区的左侧端点
// 而选区的右侧端点,采用比例尺 x 的值域上界 x.range()[1],即横坐标轴的最右端
// 所以默认选区是横跨最后一年
const defaultSelection = [x(d3.utcYear.offset(x.domain()[1], -1)), x.range()[1]];
// 创建一个容器
const gb = minimapSvg.append("g")
.call(brush) // 将前面所创建的刷选器绑定到容器上
.call(brush.move, defaultSelection); // 初始化刷选区,设置为默认选区
// 刷选发生时(选区发生改变)所触发的回调函数
// 从入参的刷选事件对象中解构出 selection 选区属性
function brushed({selection}) {
// 如果用户创建了选区
if (selection) {
// 选区 selection 是一个二元数组,其形式为 [x0, x1],其中 x0, x1 分别表示选区两端的横坐标值
// 然后使用 JS 原生方法 array.map(callbackFn, thisArg) 对数组的元素进行转换
// 通过 continue.invert(value) 将给定的值域的值 value(像素),反过来得到定义域的值(日期)
// 💡 基于选区位置反过来求出的日期并不正好是一天的开始,但是原始数据集中日期都是按天计算的,可以进行修约处理(其实也没有必要 ❓ 由于面积图是连续型的)
// 再使用 d3.utcDay 创建一个以天为间隔的 interval,通过 interval.round 对日期进行修约
// 从选区提取出聚焦的时间段 focus
// 如果选区为空,则该变量值为 [] 空数组;如果创建了选区,则该变量值为一个二元数组,表示选区两端所对应的日期
const focus = selection.map(x.invert, x).map(d3.utcDay.round);
// 然后触发主图更新
// 从 focus 里解构出缩略图选区左右两端所对应日期,作为新的横坐标轴比例尺的定义域
const [minX, maxX] = focus;
// 获取日期从 minX 到 maxX 之间的数据点,并使用 d3.max() 获取其中的(股价)最大值,作为新的纵坐标轴比例尺的定义域的上界
const maxY = d3.max(data, d => minX <= d.date && d.date <= maxX ? d.value : NaN);
// 创建比例尺 x 和 y 的副本,并更新它们的定义域范围,再重新绘制以刷新主图
updateMain(x.copy().domain(focus), y.copy().domain([0, maxY]));
}
}
// 刷选结束时所触发的回调函数
// 从入参的刷选事件对象中解构出 selection 选区属性
function brushended({selection}) {
// 如果用户没有创建选区,例如单击(而不是刷选)缩略图
if (!selection) {
// 则将选区设置回默认选区
gb.call(brush.move, defaultSelection);
}
}
其中更新主图的相关代码如下
// 方法 update 用于更新主图,它接受两个参数
// * focusX 横坐标轴比例尺
// * focusY 纵坐标轴比例尺
function updateMain(focusX, focusY) {
// 在 gx 里绘制新的横坐标轴(D3 会自动复用必要的刻度元素,刷选时会呈现切换动效)
gx.call(xAxis, focusX, height);
// 在 gy 里绘制新的纵坐标轴(D3 会自动复用必要的刻度元素,刷选时会呈现切换动效)
gy.call(yAxis, focusY, data.y);
// 在 path 里绘制面积图形状
// 调用函数 area(data, x) 返回的结果是字符串,作为 `<path>` 元素的属性 `d` 的值
path.attr("d", area(focusX, focusY));
}
数据双向同步
D3 官方还给出一个类似 Observable Plot 样例,它使用相同的数据集,也是生成了上下面积图,上面的是主图,下面的是缩略图
不同点在于两个图都是可以交互的,在上方的主图里可以进行缩放,在下方的缩略图里可以进行刷选。并且可以基于 d3-dispatch 模块实现两个可视化图的数据同步,即在一个图的操作可以同步更新另一个图
d3-dispatch 模块采用设定监听器-分发事件-触发响应的模式,实现事件驱动的交互,具体可以参考官方文档或这一篇笔记
动效
形状切换补间动画
在展示动态数据时,面积图的形状会随着数据更新而发生变化,如果添加 shape tween 形状切换补间动画可以让变化更顺滑,并使得视觉可以跟随动画来追踪数据的变化
参考
- 解读的官方样例为 Shape tweening
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
该实例演示了如何将多边形切换为圆形。其中多边形是基于一系列的地理坐标值(经过转换)绘制而成的,它边上的数据点(在页面上的坐标)都是已知的,然后限定了多边形与圆形的中心位置(对于多边形而言是指质心/重心,对于圆形而言是指圆心)和面积大小是一样的
要创建从多边形切换为圆形的补间动画,核心是求出切换过程中的一系列中间状态的形状(也就是中间状态各个数据点的坐标位置)。
从圆周上进行采样,得到与多边形相同数量的数据点,并与多边形上的数据点一一对应,则可以把多边形上的数据点作为起始值,把圆形上的数据点作为结束值。基于各个数据点的起始值和结束值对它们分别进行插值,就可以得到这些数据点的一系列中间状态的坐标值,将它们连起来可以得到一系列多边形,在切换过程依次渲染出这些多边形就构成了补间动画。
注意
这里用于实现形状切换补间动画的方法,仅适用于该示例(多边形变换为圆形),并不是通用解决方案,如果要在两个复杂的形状之间切换,路径的插值计算可以使用 flubber 库
对圆形进行采样和构建补间动画的相关代码如下
// 从圆周上进行采样,得到与多边形数量相同的数据点
// 参数 coordinates 是一个数组,包含多边形上的一系列数据点
// 具体结果可查看 👇 后面第二个 cell
function circle(coordinates) {
const circle = []; // 记录在圆周上采样的数据点
let length = 0; // 表示当前迭代的多边形上的数据点距离第一数据点的距离
const lengths = [length]; // 记录多边形是每个点与第一数据点的距离
// 多边形上的第一个数据点
let p0 = coordinates[0];
let p1;
let x;
let y;
let i = 0;
// 多边形上的数据点的总数量
const n = coordinates.length;
// Compute the distances of each coordinate.
// 通过循环所有数据点,计算多边形上的每个数据点(沿着多边形的外周)到第一数据点的距离
while (++i < n) {
// 当前所遍历的数据点 p1(则 p0 是前一个数据点)
p1 = coordinates[i];
// 当前数据点与前一个数据点的横坐标差值
x = p1[0] - p0[0];
// 当前数据点与前一个数据点的纵坐标差值
y = p1[1] - p0[1];
// 将前后两个数据点在页面上的距离,**累计**到 length 变量上
// 即表示当前所遍历的数据点距离第一个数据点的距离
lengths.push((length += Math.sqrt(x * x + y * y)));
p0 = p1; // 将当前所遍历的数据点切换为前一个数据点
}
// 使用 d3-polygon 模块所提供的一系列方法,求出多边形一些特性
const area = d3.polygonArea(coordinates); // 计算多边形的面积
// 进而将圆形面积和地图形状面积设定为一样,基于此求出圆形的半径
const radius = Math.sqrt(Math.abs(area) / Math.PI);
const centroid = d3.polygonCentroid(coordinates); // 计算多边形的质心/重心,作为变换后的圆形的圆形
// 角度偏移量,在圆周上的起始采样点所对应的角度(该角度的选取是任意的 ❓ )
const angleOffset = -Math.PI / 2; // TODO compute automatically
let angle;
// 将 2π(弧长)按照多边形的外周总长进行均分
const k = (2 * Math.PI) / lengths[lengths.length - 1];
// Compute points along the circle’s circumference at equivalent distances.
// 计算出多边形各数据点变换到圆形时,在圆周上相应的点(所对应的角度值)
// 实际是在圆周上采样,得到与多边形上相同数量的点,然后将圆形上的点与多边形周长上的点进行一一对应
i = -1;
while (++i < n) {
// 结合变量 k,则 angle 完整表达式为 angleOffset + lengths[i] * (2 * Math.PI) / lengths[lengths.length - 1]
// 其中 angleOffset 是初始偏移角度,即第一个采样点所对应的角度
// 而将 lengths[i] * (2 * Math.PI) / lengths[lengths.length - 1] 看作 (2 * Math.PI) * (lengths[i] / lengths[lengths.length - 1])
// 则 lengths[i] / lengths[lengths.length - 1] 表示第 i 个采样点所对应的多边形上的点与多边形上的第一个点的距离为 lengths[i],与多边形的周长 lengths[lengths.length - 1] 的比值,表示多边形上的第 i 个点的距离占总长度的比例,将其与 (2 * Math.PI) 相乘,得到在圆周上的采样点相应的角度值
angle = angleOffset + lengths[i] * k;
// 基于圆心坐标和半径,以及该采样点的角度值,得到该采样点的坐标值 [x, y]
circle.push([
centroid[0] + radius * Math.cos(angle), // 横坐标值:圆心横坐标值 + r * cos(angle)
centroid[1] + radius * Math.sin(angle) // 纵坐标值:圆心纵坐标值 + r * sin(angle)
]);
}
// 返回采样的结果
return circle;
}
/**
*
* 创建切换动画
*
*/
loop(); // 开始切换形状
// 异步操作,在执行完当前动画后,才开始新一轮的动画
async function loop() {
// 使用 <path> 元素将线面积形状绘制到页面上
await path
// 通过设置 `<path>` 元素的属性 `d` 绘制出路径的原始形状,多边形
.attr("d", d0)
// 设置过渡动效(通过更改 `<path>` 的属性 d 实现)
// 通过 selection.transition() 创建过渡管理器
// 过渡管理器和选择集类似,有相似的方法,例如为选中的 DOM 元素设置样式属性
// 具体参考官方文档 https://d3js.org/d3-transition
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-transition
.transition()
.duration(5000) // 设置过渡的时间
// 通过方法 `transition.attr(attrName, value)` 设置元素的属性 `attrName`,直接设置了目标值 `value`(过渡结束时的最终值),而不需要设置过渡期间各个时间点的值(因为 D3 会根据属性值的数据类型,自动调用相应插值器)
// 关于方法 `transition.attr()` 的详细介绍可以参考这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-transition#过渡参数配置
// 💡 另一类似的方法是 `transition.attrTween()` 也是用于设置元素的属性 `attrName`,都是自由度更高,可以自定义插值器 `factory` 用于进行插值计算,即计算过渡期间属性 `attrName` 在各个时间点的值
.attr("d", d1)
// 然后通过 `transition.transition()` 基于原有的过渡管理器所绑定的选择集合,创建一个新的过渡管理器
// 新的过渡管理器会**继承了原有过渡的名称、时间、缓动函数等配置**
// 而且新的过渡会**在前一个过渡结束后开始执行**
// 一般通过该方法为同一个选择集合设置一系列**依次执行的过渡动效**
.transition()
.delay(5000) // 设置过渡的延迟/等待时间
// 这里是将面积形状从圆形切换回多边形
.attr("d", d0)
// 最后通过方法 transition.end() 返回一个 Promise,仅在过渡管理器所绑定的选择集合的所有过渡完成时才 resolve
// 这样就可以在当前的过渡结束时,才做执行后面操作(重复下一轮动画)
.end();
// 使用浏览器原生方法 requestAnimationFrame(callback) 告诉浏览器希望执行一个动画
// 重新执行 loop 函数
requestAnimationFrame(loop);
}
提示
如果要实现不同路径切换的补间动画可以查看另一个 Observable Notebook Path tween 或另一篇*笔记*
河流图切换动效
参考
- 解读的官方样例为 Streamgraph transitions
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
该实例的大部分代码都和静态河流图类似,不同在于数据会不断更新,并在重新渲染河流图的形状时添加了切换动效,相关代码如下
// 执行无限循环,不断更新河流图的数据
(async function () {
while (true) {
// yield svg.node();
// 异步操作,在当前过渡完成时(Promise 才会 resolve),才会进入下一个循环周期(开始新一轮的过渡动画 )
await path
.data(randomize) // 绑定新生成的数据集
// 设置过渡动效(通过更改 `<path>` 的属性 d 实现)
// 通过 selection.transition() 创建过渡管理器
// 过渡管理器和选择集类似,有相似的方法,例如为选中的 DOM 元素设置样式属性
// 具体参考官方文档 https://d3js.org/d3-transition
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-transition
.transition()
.delay(1000) // 设置过渡的延迟/等待时间
.duration(1500) // 设置过渡的时间
// 重绘各堆叠的面积形状
.attr("d", area)
// 最后通过方法 transition.end() 返回一个 Promise,仅在过渡管理器所绑定的选择集合的所有过渡完成时才 resolve
// 这样就可以在当前的过渡结束时,才做执行后面操作(重复下一轮动画)
.end();
}
})();
变体
堆叠式面积图
堆叠面积图和普通的面积图类似,而实际上是由多个系列的小面积(一般采用不同的颜色进行标记)依次堆叠构成的,所以与一般的面积图相比,它所对应的数据格式,以及可视化时所使用的 D3 模块也会不同
参考
- 解读的官方样例为 Stacked area chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
其中主要不同是需要使用 d3-shape 模块 里面的关于 堆叠 stack 的一些方法
使用方法 d3.stack() 创建一个堆叠生成器(以下称为 stack)对数据进行转换,便于后续绘制堆叠图
提示
关于堆叠生成器的详细介绍可以查看这一篇笔记
例如对于如下数据
// 原始数据样例
// 数组每个元素都是一条数据记录,它包含了多个系列的数据(不同类型的水果在当月的销量)
const data = [
{month: new Date(2015, 0, 1), apples: 3840, bananas: 1920},
{month: new Date(2015, 1, 1), apples: 1600, bananas: 1440},
];
// 创建一个堆叠生成器
const stack = d3.stack()
.keys(["apples", "bananas"]) // 设定系列名称
// 对原数据进行转换
const series = stack(data);
console.log(series)
经过堆叠生成器的转换,可以得到一个嵌套数组,其中每一个元素(嵌套的数组)就是一个系列
// 返回的结果,转换后得到各系列的数据
[
// 每一个系列的数据都独立「抽取」出来组成一个数组
// apple 系列数据
[
// 每个元素都是 apple 的月销量数据点
// 前两个数值类似于面积图中的下边界线和上边界线
// data 对象保留了转换前该数据点对应的原始数据来源
[0, 3840, data: {month: 2014-12-31T16:00Z, apples: 3840, bananas: 1920}], // 12 月销量
[0, 1600, data: {month: 2015-01-31T16:00Z, apples: 1600, bananas: 1440}], // 1 月销量
key: "apples", // 该系列对应的 key(名称)
index: 0 // 该系列在 series 中的顺序(即对应于堆叠条形图中该系列叠放的次序)
],
// bananas 系列数据
[
[3840, 5760, data: {month: 2014-12-31T16:00Z, apples: 3840, bananas: 1920}],
[1600, 3040, data: {month: 2015-01-31T16:00Z, apples: 1600, bananas: 1440}],
key: "bananas",
index: 1
]
]
在该样例中,使用堆叠器对原始数据进行转换的相关代码如下
/**
*
* 对数据进行转换
*
*/
// 决定有哪些系列进行堆叠可视化
// 通过堆叠生成器对数据进行转换,便于后续绘制堆叠图
// 返回一个数组,每一个元素都是一个系列(整个面积图就是由多个系列堆叠而成的)
// 而每一个元素(系列)也是一个数组,其中每个元素是属于该系列的一个数据点,例如在本示例中,有 122 个月份的数据,所以每个系列会有 122 个数据点
// 具体可以参考官方文档 https://d3js.org/d3-shape/stack
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#堆叠生成器-stacks
const series = d3.stack()
// 设置系列的名称(数组)
// 使用 d3.union() 从所有数据点的属性 industry 的值中求出并集,返回一个集合 set
// 即有哪几种行业
// 该方法来自 d3-array 模块,具体可以参考官方文档 https://d3js.org/d3-array/sets#union
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-process#集合
// D3 为每一个系列都设置了一个属性 key,其值是系列名称(生成面积图时,系列堆叠的顺序就按照系列名称的排序)
.keys(d3.union(data.map(d => d.industry)))
// 设置各系列的数据读取函数
// 在调用堆叠生成器对原始数据进行转换过程中,每一个原始数据 d 和系列名称 key(就是在 stack.keys([keys]) 设定的数组中的元素)会作为入参,分别调用该函数,以从原始数据中获取相应系列的数据
// 数据读取函数的逻辑要如何写,和后面 👇👇 调用堆叠生成器时,所传入的数据格式紧密相关
// 因为传入的数据 d3.index(data, d => d.date, d => d.industry) 是一个嵌套映射
// 在遍历数据点时(映射会变成一个二元数组 [键名,值] 的形式),要从中获取相应系列的数据
// 首先要对当前所遍历的数据点进行解构 [key, value] 第二个元素就是映射(第一层)的值,它也是一个映射
// 然后再通过 D.get(key) 获取相应系列(行业)的数据(一个对象)
// 堆叠的数据是失业人数,所以最后返回的是该系列数据(对象)的 unemployed 属性
.value(([, D], key) => D.get(key).unemployed)
// 调用堆叠生成器,传入数据
// 传入的数据并不是 data 而是经过 d3.index() 进行分组归类转换的
(d3.index(data, d => d.date, d => d.industry));
另外为了便于区分不同系列,一般需要设置颜色比例尺,将不同系列映射到不同的颜色上,即不同的堆叠层会填充上不同的颜色,以下关于颜色比例尺的核心代码
// 设置颜色比例尺
// 为不同系列设置不同的配色
// 使用 d3.scaleOrdinal() 排序比例尺 Ordinal Scales 将离散型的定义域映射到离散型值域
// 具体参考官方文档 https://d3js.org/d3-scale/ordinal
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#排序比例尺-ordinal-scales
const color = d3.scaleOrdinal()
// 设置定义域范围
// 各系列的名称,即 14 种行业
.domain(series.map(d => d.key))
// 设置值域范围
// 使用 D3 内置的一种配色方案 d3.schemeTableau10
// 它是一个数组,包含一些预设的颜色(共 10 种)
// 具体可以参考官方文档 https://d3js.org/d3-scale-chromatic/categorical#schemeTableau10
// 这里的系列数量是 14 种,而 d3.schemeTableau10 配色方案种只有 10 种颜色
// 💡 排序比例尺会将定义域数组的第一个元素映射到值域的第一个元素,依此类推。如果值域的数组长度小于定义域的数组长度,则值域的元素会被从头重复使用进行映射,即进行「循环」映射
// 所以仔细查看会发现有些系列所对应的颜色有重复
// 但是在堆叠图中只要相邻的系列不采用相同的颜色,即可达到区分的作用,所以系列数量和颜色数量不相等也不影响实际效果
// 也可以查看官方文档 https://d3js.org/d3-scale-chromatic/categorical 采用其他(提供更多颜色的)配色方案,让各种系列都有唯一的颜色进行标识
.range(d3.schemeTableau10);
标准化的堆叠式面积图
参考
- 解读的官方样例为 Normalized stacked area chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
标准化的堆叠式面积图与普通的堆叠面积图相比,在代码上大部分都是相同的,相当于只是将基线函数更改为 d3.stackOffsetExpand 相关的代码如下
const series = d3.stack()
// 💡 设置堆叠基线函数,这里采用 D3 所提供的一种基线函数 d3.stackOffsetExpand
// 对数据进行标准化(相当于把各系列的绝对数值转换为所占的百分比),基线是零,上边界线是 1
// 所以每个横坐标值所对应的总堆叠高度都一致(即纵坐标值为 1)
// 具体可以参考官方文档 https://d3js.org/d3-shape/stack#stackOffsetExpand
.offset(d3.stackOffsetExpand)
// 设置系列的名称(数组)
// 使用 d3.union() 从所有数据点的属性 industry 的值中求出并集,返回一个集合 set
// 即有哪几种行业
// 该方法来自 d3-array 模块,具体可以参考官方文档 https://d3js.org/d3-array/sets#union
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-process#集合
// D3 为每一个系列都设置了一个属性 key,其值是系列名称(生成面积图时,系列堆叠的顺序就按照系列名称的排序)
.keys(d3.union(data.map(d => d.industry)))
// 设置各系列的数据读取函数
// 在调用堆叠生成器对原始数据进行转换过程中,每一个原始数据 d 和系列名称 key(就是在 stack.keys([keys]) 设定的数组中的元素)会作为入参,分别调用该函数,以从原始数据中获取相应系列的数据
// 数据读取函数的逻辑要如何写,和后面 👇👇 调用堆叠生成器时,所传入的数据格式紧密相关
// 因为传入的数据 d3.index(data, d => d.date, d => d.industry) 是一个嵌套映射
// 在遍历数据点时(映射会变成一个二元数组 [键名,值] 的形式),要从中获取相应系列的数据
// 首先要对当前所遍历的数据点进行解构 [key, value] 第二个元素就是映射(第一层)的值,它也是一个映射
// 然后再通过 D.get(key) 获取相应系列(行业)的数据(一个对象)
// 堆叠的数据是失业人数,所以最后返回的是该系列数据(对象)的 unemployed 属性
.value(([, D], key) => D.get(key).unemployed)
// 调用堆叠生成器,传入数据
// 传入的数据并不是 data 而是经过 d3.index() 进行分组归类转换的
(d3.index(data, d => d.date, d => d.industry));
河流图
河流图 Streamgraph 是堆叠式面积图的一种变体,它的构建方法和常见的堆叠式面积图大体相同,只是在堆叠算法和基线设置有所不同。(由于河流图采用特殊的布局)可能还需要对纵坐标轴的刻度值进行相应的处理。
参考
- 解读的官方样例为 Streamgraph
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
河流图的基线并不是零(并不在横坐标轴),而是在 svg 图的中间,所以需要采用不同的基线函数 d3.stackOffsetWiggle,一般配合的排序函数是 d3.stackOrderInsideOut 让河流图看起来更美观、流畅、易读
提示
可以阅读相关文章 Stacked Graphs – Geometry & Aesthetics 对这种布局的介绍
与河流图相关的数据转换(堆叠器的配置)核心代码如下
/**
*
* 对数据进行转换
*
*/
// 决定有哪些系列进行堆叠可视化
// 通过堆叠生成器对数据进行转换,便于后续绘制堆叠图
// 返回一个数组,每一个元素都是一个系列(整个面积图就是由多个系列堆叠而成的)
// 而每一个元素(系列)也是一个数组,其中每个元素是属于该系列的一个数据点,例如在本示例中,有 122 个月份的数据,所以每个系列会有 122 个数据点
// 具体可以参考官方文档 https://d3js.org/d3-shape/stack
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#堆叠生成器-stacks
const series = d3.stack()
// 设置基线函数,通过更新堆叠图的上下界的值,可以调整图形整体的定位
// D3 提供了一系列内置的基线函数,它们的具体效果可以参考 https://d3js.org/d3-shape/stack#stack-offsets
// 默认使用内置基线函数 d3.stackOffsetNone 以零为基线
// 这里使用另一种内置基线函数 d3.stackOffsetWiggle 通过移动基线,以最大程度地减小各系列的「振幅」(即各系列沿着横轴上下摆动的幅度),让河流图看起来更美观、流畅、易读
// 它一般用在河流图中,并与排序函数 d3.stackOrderInsideOut 配合使用
// 可以阅读相关文章 https://leebyron.com/streamgraph/ 对这种算法的介绍
.offset(d3.stackOffsetWiggle)
// 设置排序函数,即决定堆叠图中各系列的叠放次序
// 该函数返回的是一个数组(称为排序数组 order),里面的元素是一个表示索引的数值,依次对应于系列名称数组的元素,表示各系列的排序/叠放优先次序
// D3 提供了一系列内置的排序函数,它们的具体效果可以参考 https://d3js.org/d3-shape/stack#stack-orders
// 默认使用内置排序函数 d3.stackOrderNone 它不对排序/叠放次序进行改变
// 即按照系列名称数组(通过方法 stack.keys() 所设置的)来排序
// 这里使用了另一种内置的排序函数 d3.stackOrderInsideOut
// 它是根据各系列的最大值进行排序,将较大的系列置于堆叠图的中间(一般用于河流图中)
// 可以阅读相关文章 https://leebyron.com/streamgraph/ 对这种布局的介绍
.order(d3.stackOrderInsideOut)
// 设置系列的名称(数组)
// 使用 d3.union() 从所有数据点的属性 industry 的值中求出并集,返回一个集合 set
// 即数据集中包含了哪几种(名称不同的)行业
// 该方法来自 d3-array 模块,具体可以参考官方文档 https://d3js.org/d3-array/sets#union
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-process#集合
// D3 为每一个系列都设置了一个属性 key,其值是系列名称(生成面积图时,系列堆叠的顺序就按照系列名称的排序)
.keys(d3.union(data.map(d => d.industry)))
// 设置各系列的数据读取函数
// 在调用堆叠生成器对原始数据进行转换过程中,每一个原始数据 d 和系列名称 key(就是通过方法 stack.keys() 所设置的数组中的元素)会作为入参,分别调用该函数,以从原始数据中获取相应系列的数据
// 数据读取函数的逻辑要如何写,和后面 👇👇 调用堆叠生成器时,所传入的数据格式紧密相关
// 因为传入的数据 d3.index(data, d => d.date, d => d.industry) 是一个嵌套映射
// 在遍历数据点时(映射会变成一个二元数组 [键名,值] 的形式),要从中获取相应系列的数据
// 首先要对当前所遍历的数据点进行解构 [key, value] 第二个元素就是映射(第一层)的值,它也是一个映射
// 然后再通过 D.get(key) 获取相应系列(行业)的数据(一个对象)
// 堆叠的数据是失业人数,所以最后返回的是该系列数据(对象)的 unemployed 属性
.value(([, D], key) => D.get(key).unemployed)
// 调用堆叠生成器,传入数据
// 传入的数据并不是 data 而是经过 d3.index() 进行分组归类转换的
(d3.index(data, d => d.date, d => d.industry));
// 💡 虽然所绘制的河流图中,所对应的纵坐标值都是正数,这是由于坐标轴的刻度值是经过处理的,实际上在零点下方的刻度值是负数
// 相应地经过以上堆叠器转换所得的(表示上下界)数据中是有正负值,在纵坐标轴的零点之上的堆叠面积所对应的数据为正,在零点之下堆叠的面积所对应的数据为负
另外还需要对纵坐标轴的刻度值进行处理,相关代码如下
// 绘制纵坐标轴
// 它和一般图表的坐标轴不一样,因为河流图的基线位于 svg 的中间(不一定是零点)
// 💡 所以纵坐标轴的零点不一定在 x 轴的位置
svg.append("g")
// 通过设置 CSS 的 transform 属性将纵向坐标轴容器「移动」到左侧
.attr("transform", `translate(${marginLeft},0)`)
// 纵轴是一个刻度值朝左的坐标轴
// 通过 axis.ticks(count) 设置刻度数量的参考值(避免刻度过多导致刻度值重叠而影响图表的可读性)
// 然后使用方法 axis.tickFormat() 设置刻度值的格式
// 💡 数据集 series 是对原始数据处理后所得的,为了方便实现河流图的布局,它是含有正负值
// 然后采用比例尺 y 将 series 数据映射为河流图,则基于比例尺 y 所生成的纵坐标轴的刻度值也有正负值(与 series 数据相对应),但是实际上失业人数并不存在负数
// 所以这里需要对刻度值进行处理,使用 Math.abs() 取绝对值,将负值变成正值,所以最终纵坐标轴的刻度值在零点上下都是正值
// 并且使用 number.toLocaleString("en-US") 格式化数字(转换为字符串,以符合特定的语言环境的表达方式)
.call(d3.axisLeft(y).ticks(height / 80).tickFormat((d) => Math.abs(d).toLocaleString("en-US")))
// 删掉上一步所生成的坐标轴的轴线(它含有 domain 类名)
.call(g => g.select(".domain").remove())
// 复制了一份刻度线,用以绘制图中横向的网格参考线
.call(g => g.selectAll(".tick line").clone()
// 调整复制后的刻度线的终点位置(往右移动)
.attr("x2", width - marginLeft - marginRight)
.attr("stroke-opacity", 0.1))
// 为坐标轴添加额外信息名称(一般是刻度值的单位等信息)
.call(g => g.append("text")
// 将该文本移动到坐标轴的顶部(即容器的左上角)
.attr("x", -marginLeft)
.attr("y", 10)
.attr("fill", "currentColor") // 设置文本的颜色
.attr("text-anchor", "start") // 设置文本的对齐方式
.text("↑ Unemployed persons")); // 设置文本内容
带状图
Band Chart 带装图是面积图的一种变形;也可以称为范围面积图,因为它通过上边界和下边界展示数据范围的变化
提示
带状图也常常与折线图一起使用,构成一种增强型的折线图,称为 band line
上图摘自 seaborn.lineplot
例如折线图描述均值的变化趋势,采用高亮的颜色,它展示了具代表性的数据是如何变化的;而带状图描述最小值和最大值的变化趋势,作为「背景」阴影区域,补充说明数据的整体是如何变化的
参考
- 解读的官方样例为 Band chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
- 推荐阅读文章 An Underrated Chart Type: The Band Chart 作者对带状图的优缺点进行分析,并讨论了其适用场景
构建该类型的可视化图的代码和普通面积图基本一样,区别在于普通面积图的下边界线的纵坐标的读取函数一般设置为 y(0),因为它们的下边界线通常是横坐标轴,所以它的 y 值始终是 0;而带状图的下边界线的纵坐标读取函数则会复杂些,它会基于不同数据点而生成不同的值(而不是恒为 0)
该实例中关于面积生成器的核心代码如下:
/**
*
* 绘制面积图内的面积形状
*
*/
// 使用 d3.area() 创建一个面积生成器
// 面积生成器会基于给定的数据生成面积形状
// 调用面积生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/area
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
const area = d3.area()
// 设置下边界线横坐标读取函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,以返回该数据所对应的横坐标
// 这里基于每个数据点的日期(时间)d.date 并采用比例尺 x 进行映射,计算出相应的横坐标
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数
// 这里的面积图的下边界线是横坐标轴,所以它的 y 值始终是 0,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y0(y(0))
// 设置上边界线的纵坐标的读取函数
.y1(d => y(d.close));
差异图
Difference Chart 差异图如果不标注颜色其实就是一个 Area Chart 面积图(具体来说更像是 Band Chart,它的下界一般不是横轴)
但标注上颜色就显得不同了,该类型的图形是为了凸显两个研究目标之间的差异,而且绘制方式也和一般面积图不同。
理解差异图时可以将其看作由两条折线构成(不是单纯的面积图的上界和下界),例如在以下示例中加粗的线就表示三藩市的每日平均温度随时间的变化,那么相应地面积图的另一条边就是纽约的每日平均温度随时间的变化。
而将两条线之间的区域填充上颜色就构成了差异图,可以通过面积的大小直观地感知两者差距的大小(以及如何变化)。
并且可以根据两个折线的相对位置关系,为相应的面积区域标注不同的颜色,以更直观地凸显出差异的不同情况(谁的值更大),在以下实例中当三藩市的温度更高的日子面积标为橙色,当三藩市的温度更低的日子面积标为蓝色。
参考
- 解读的官方样例为 Difference chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
在绘制差异图时与一般的面积图有所不同,首先是面积区域只是局限在两个折线之间,而且需要根据折线的相对位置填充上不同的颜色,所以一张差异图一般需要分两个步骤来绘制。
在以上示例中使用 <clipPath> 对普通的面积图(或它的互补图形)进行裁剪,只绘制出折线之间的面积,不同颜色的面积分开绘制,具体的
剪贴路径
剪贴路径 <clipPath> 可以自定义视口的形状和大小,作用于元素上就可以达到裁剪的效果
在以上示例通过设置上下错位的剪贴路径 <clipPath> 与面积路径 <path>(以达到上下钳制/约束的效果),可以基于普通的面积图(或它的互补图形)裁剪出所需的区域
该实例中关于绘制差异图的核心代码如下:
/**
*
* 绘制面积图内的面积形状
*
*/
// 创建一个 <clipPath> 元素(一般具有属性 id 以便被其他元素引用),其作用充当一层剪贴蒙版,具体形状由其包含的元素决定
// 它一般与其他元素一起使用(通过属性 clip-path 来指定),为其他元素自定义了视口
// 即在 <clipPath> 所规定的区域以外的部分都会被裁剪掉
// 具体介绍可以参考 https://developer.mozilla.org/en-US/docs/Web/SVG/Element/clipPath
svg.append("clipPath")
// 为 <clipPath> 设置属性 id
.attr("id", "above")
// 在其中添加 <path> 子元素,以设置剪切路径的形状
.append("path")
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
// 💡 调用面积生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/area
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
.attr("d", d3.area()
// 设置两点之间的曲线插值器,这里使用 D3 所提供的一种内置曲线插值器 d3.curveStep
// 该插值效果是在两个数据点之间,生成阶梯形状的线段(作为面积图的边界)
// 具体效果参考 https://d3js.org/d3-shape/curve#curveStep
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,以返回该数据所对应的横坐标
// 这里基于每个数据点的日期(时间)d.date 并采用比例尺 x 进行映射,计算出相应的横坐标
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数,它始终是 0(即位于 svg 的顶部位置)
.y0(0)
// 设置上边界线的纵坐标的读取函数,基于 d.value1 纽约的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value1)));
// 正如该剪贴路径的 id 名称一样,该剪贴蒙版的显示区域/视口范围位于 svg 的上半部分,即从 svg 的顶部,直到橙色面积的下边缘
// 通过该剪切路径的约束,可以呈现由两地之间较低的日间温度所构成的的折线
// 创建一个 <clipPath> 元素
svg.append("clipPath")
// 为 <clipPath> 设置属性 id
.attr("id","below")
// 在其中添加 <path> 子元素,以设置剪切路径的形状
.append("path")
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
.attr("d", d3.area()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数,它始终是 height(即位于 svg 的底部位置,即横坐标轴)
.y0(height)
// 设置上边界线的纵坐标的读取函数,基于 d.value1 纽约的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value1)));
// 正如该剪贴路径的 id 名称一样,该剪贴蒙版的显示区域/视口范围位于 svg 的下部分,即从 svg 的底部,直到蓝色面积的下边缘
// 通过该剪切路径的约束,可以呈现由两地之间较高的日间温度所构成的的折线
// 💡 通过以上两个 <clipPath> 对面积图的共同约束,就可以裁剪出所需的差异图
// 绘制表示三藩市温度的面积图,并通过 <clipPath> 进行裁剪
svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 设置属于 clip-path 以采用前面预设的 <clipPath id="above"> 对图形进行裁剪/约束
.attr("clip-path", "url(#above)")
.attr("fill", colors[1]) // 设置填充颜色为橙色
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
.attr("d", d3.area()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数,它始终是 height(即位于 svg 的底部位置,即横坐标轴)
.y0(height)
// 设置上边界线的纵坐标的读取函数,基于 d.value0 三藩市的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value0)));
// 💡 通过 <clipPath id="above"> 对面积图的裁剪,只显示三藩市温度面积图的部分,即橙色的部分,由于这部分的区域(所对应的时间里)纽约的温度更低
// 绘制表示纽约温度的面积图,并通过 <clipPath> 进行裁剪
svg.append("path") // 使用路径 <path> 元素绘制面积形状
// 设置属于 clip-path 以采用前面预设的 <clipPath id="below"> 对图形进行裁剪/约束
.attr("clip-path", "url(#below)")
.attr("fill", colors[0]) // 设置填充颜色为浅蓝色
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
.attr("d", d3.area()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
.x(d => x(d.date))
// ⚠️ 设置下边界线的纵坐标的读取函数,它始终是 0(即位于 svg 的顶部位置)
// ⚠️ 和普通的面积图有所不同,可以理解为真正表示纽约温度的面积图是透明的,而(这里绘制的)与它互补的部分则填充为浅蓝色
// ⚠️ 结合 <clipPath> 的裁剪,剩余的部分就是三藩市温度比纽约高的日子
.y0(0)
// 设置上边界线的纵坐标的读取函数,基于 d.value0 三藩市的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value0)));
// 绘制一条黑色的线,表示三藩市的温度随时间的变化
svg.append("path") // 使用路径 <path> 元素绘制折线
.attr("fill", "none") // 由于折线不需要填充颜色,所以属性 fill 设置为 none
.attr("stroke", "black") // 设置折线的描边颜色为黑色
.attr("stroke-width", 1.5) // 设置描边的宽度
.attr("stroke-linejoin", "round") //
.attr("stroke-linecap", "round") // 设置折线之间的连接样式(圆角让连接更加平滑)
// 使用方法 d3.line() 创建一个线段生成器,线段生成器会基于给定的数据(svg 所绑定的数据)生成线段(或曲线)
// 调用线段生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/line 或 https://github.com/d3/d3-shape/tree/main#lines
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#线段生成器-lines
.attr("d", d3.line()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 该函数会在调用线段生成器时,为数组中的每一个元素都执行一次横坐标读取函数和纵坐标读取函数,以返回该数据所对应的横纵坐标值
// 设置横坐标读取函数
// 这里基于每个数据点的日期(时间)d.date 并采用比例尺 x 进行映射,计算出相应的横坐标
.x(d => x(d.date))
// 设置纵坐标读取函数
// 这里基于每个数据点的三藩市的温度 d.value0 并采用比例尺 y 进行映射,计算出相应的纵坐标
.y(d => y(d.value0)));
提示
另外在复现以上官方示例时,还制作了一个简化版本 difference-chart-v2
不需要使用 <clipPath> 对原始面积图(或它的互补图形)进行裁剪,而是根据三藩市于纽约的温度的关系来控制面积图的上边界线/下边界线,直接分别构建出两种不同颜色的面积,最终渲染生成的可视化图形是相同的
相关代码如下:
/**
*
* 绘制面积图内的面积形状
*
*/
// 绘制表示橙色的面积图(三藩市的温度高于纽约),面积图的上边界是三藩市的温度,下边界是纽约的温度,填充色为橙色
// 而对于三藩市低于纽约的日子,则不绘制面积图(可以将这段时间的面积图的下边界也设定为三藩市的温度,则该时间段的面积图绘制为一条线,再将折线的描边设置为透明即可)
svg.append("path") // 使用路径 <path> 元素绘制面积形状
.attr("fill", colors[1]) // 设置填充颜色为橙色
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
.attr("d", d3.area()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数,它始终是 height(即位于 svg 的底部位置,即横坐标轴)
.y0(d => d.value0 > d.value1 ? y(d.value1) : y(d.value0))
// 设置上边界线的纵坐标的读取函数,基于 d.value0 三藩市的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value0)));
// 绘制表示浅蓝色的面积图(三藩市的温度低纽约),面积图的上边界是纽约的温度,下边界是三藩市的温度,填充色为浅蓝色
// 而对于三藩市高于纽约的日子,则不绘制面积图(可以将这段时间的面积图的下边界也设定为纽约的温度,则该时间段的面积图绘制为一条线,再将折线的描边设置为透明即可)
svg.append("path") // 使用路径 <path> 元素绘制面积形状
.attr("fill", colors[0]) // 设置填充颜色为浅蓝色
// 使用方法 d3.area() 创建一个面积生成器,它会根据给定的数据(svg 所绑定的数据)设置 <path> 路径形状
.attr("d", d3.area()
// 设置两点之间的曲线插值器
.curve(d3.curveStep)
// 设置下边界线横坐标读取函数
.x(d => x(d.date))
// 设置下边界线的纵坐标的读取函数,它始终是 height(即位于 svg 的底部位置,即横坐标轴)
.y0(d => d.value0 > d.value1 ? y(d.value1) : y(d.value0))
// 设置上边界线的纵坐标的读取函数,基于 d.value1 纽约的温度,并采用比例尺 y 进行映射,得到纵坐标轴在 svg 中的坐标位置
.y1(d => y(d.value1)));
山脊线图
山脊线图 Ridgeline plots 可以展示多个系列的数据
别名
它也被称为 joy plot,因为在 Joy Division 乐队的专辑《Unknown Pleasures》的封面上出现了山脊线图
这个 NoteBook 使用 D3.js 复刻了该图,可以将其视为山脊线图(面积图)的折线图版本
展示多系列数据的面积图对比
山脊线图 Ridgeline plots、地平线图 Horizon charts、面积图矩阵 Small-multiple area charts 都可以用于展示多个系列的数据,但采用的方式各不相同,所以在绘图高度有限的前提下可提供的精度也有差异:
- 面积图矩阵:通过将整体划分出多个小区域,就可以分别展示不同系列的数据,但是相应地每个小区域可展示的精度就变得更小了
- 山脊图:通过将多个面积图尽可能地重叠,以展示更多的系列数据,只要图形之间重叠部分足够大,就可以尽可能地降低对精度的影响(虽然会有可能出现由于重叠遮盖,而无法准确显示一些较低的数值)
- 地平线图:通过对面积图纵向切片分段,再将切片重叠在一起,从而控制各个面积图的纵向高度(到相同的高度),但是这种处理方式会掩盖掉面积图的真实高度,为了弥补这个缺点需要为面积图添加颜色和设置透明度,以颜色的深浅来编码面积的高低。这样的转换会显著地降低精度(颜色深浅相对更难定量),但是很适合在有限的空间展示大量不同系列的数据,颜色也可以让读者对各系列数据之间的差异有更快速和直观的感受
参考
- 解读的官方样例为 Ridgeline plot
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
山脊线图是由多个小面积图堆叠起来而构成的,采用点状比例尺将各个小面积图沿着纵向排列,相关代码如下
// 设置山脊图的纵坐标轴的比例尺(针对整体,用于将各个面积图在纵向定位)
// 在山脊图中多个面积图纵向铺开,在纵坐标轴上分别对应标注出不同地点,使用 d3.scalePoint 构建一个点状比例尺
// 该比例尺将基于定义域数组的离散元素(不同的地名)的数量,将值域的范围分割为等距的各段,各个分隔点与定义域中的离散元素依次映射
// 点状比例尺 Point Scales 和带状比例尺类似,就像是将 band 的宽度设置为 0
// 具体可以参考官方文档 https://d3js.org/d3-scale/point
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-scale#点状比例尺-point-scales
const y = d3.scalePoint()
// 设置定义域范围,参数是一个数组,包含所需映射的系列名称
// 使用 JS 数组的原生方法 array.map() 对数组 series 进行处理
// 提取出各系列的名称(地名) d.name 构成一个新的数组
.domain(series.map(d => d.name))
// 设置值域范围
// svg 元素的高度(减去留白区域)
.range([marginTop, height - marginBottom]);
// ...
// 创建容器
// 首先建一个整体的容器
const group = svg.append("g")
.selectAll("g") // 返回一个选择集,其中虚拟/占位元素是一系列的 <g> 元素,它们分别作为各个系列的面积图的容器
.data(series) // 绑定数据,每个容器 <g> 元素对应一个系列的数据
.join("g") // 将这些 <g> 元素绘制到页面上
// 通过设置 CSS 的 transform 属性将各系列的容器定位不同的位置
// 基于各系列的名称(地点名)并采用比例尺 y 进行映射 y(d.name) 计算出相应(分隔点)的纵坐标值,然后向下偏移 1px ❓ 可能是要覆盖掉横坐标轴的轴线
.attr("transform", d => `translate(0,${y(d.name) + 1})`);
而绘制各个小面积图的步骤和绘制一个普通面积图类似,但是由于它们之间需要重叠,所以设置它们的纵向高度的方式会有所不同。(普通的面积图的纵向高度就是 svg 的高度)各个小面积图的默认最大高度可以先采用点状比例尺的步长作为基础 step,然后再乘上一个特定的倍数 k 以控制相邻面积图之间的重叠程度,即各个小面积图的纵向(最大)高度为 k*step,相关代码如下
// 设置面积图的纵坐标轴比例尺(针对各个面积图,用于计算它们的上边界线的纵坐标值)
// 面积图的纵轴数据是连续型的数值(车流量),使用 d3.scaleLinear 构建一个线性比例尺
const z = d3.scaleLinear()
// 设置定义域范围
// [0, ymax] 其中 ymax 是车流量的最大值
// 首先使用 d3.max(d.values) 计算当前所遍历的系列的各个时间点的车流量中的最大值
// 然后再一次使用 d3.max() 计算所有系列中的最大值
// 并使用 continuous.nice() 方法编辑定义域的范围,通过四舍五入使其两端的值更「整齐」nice
.domain([0, d3.max(series, d => d3.max(d.values))]).nice()
// 设置值域范围
// 定义域的最小值都映射到 0,定义域的最大值都映射到 -overlap*y.step()
// 其中 y 是点状比例尺,调用方法 y.step() 返回步长,即分隔点之间的距离
// 而 overlap 是前面所定义的一个变量,调节/控制相邻面积图之间的重叠程度
// ⚠️ 根据 svg 的坐标系统,左上角才是坐标 (0,0),而向右和向下是正方向(坐标值为正值)
// 所以在前面添加的负号 -overlap * y.step() 表示经过比例尺 z 映射后,各面积图的上边界线都是负值,即它们都是朝上的
// 💡 最初各个面积图都是定位到 svg 的顶部,它们的(y 值)都是在 [0, -overlap*y.step] 范围中,即最大占据的空间/高度是 overlap*y.step
// 然后它们会根据 y 比例尺重定位到点状比例尺的分隔点上,形成垂直排布
// 如果 overlap=1 则各个面积图所占据的(最大)纵向空间正好是 y.step() 分隔点的间距,所以相邻面积图之间不会重叠;如果 overlap > 1 则面积图占据的纵空间比点状比例尺的间隔更大,则相邻面积图之间就可能发生重叠
.range([0, -overlap * y.step()]);
// ...
/**
*
* 绘制山脊线图
*
*/
// Create the area generator and its top-line generator.
// 使用 d3.area() 创建一个面积生成器,它适用于生成各个系列的面积图
// 面积生成器会基于给定的数据生成面积形状
// 调用面积生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/area
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
const area = d3.area()
// 设置两点之间的曲线插值器,这里使用 D3 所提供的一种内置曲线插值器 d3.curveBasis
// 该插值效果是在两个数据点之间,生成三次样条曲线 cubic basis spline
// 具体效果参考 https://d3js.org/d3-shape/curve#curveBasis
.curve(d3.curveBasis)
// 💡 调用面积生成器方法 area.defined() 设置数据完整性检验函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,返回布尔值,以判断该元素的数据是否完整
// 该函数传入三个入参,当前的元素 `d`,该元素在数组中的索引 `i`,整个数组 `data`
// 当函数返回 true 时,面积生成器就会执行下一步(调用坐标读取函数),最后生成该元素相应的坐标数据
// 当函数返回 false 时,该元素就会就会跳过,当前面积就会截止,并在下一个有定义的元素再开始绘制,反映在图上就是一个个分离的面积区块
// 具体可以参考官方文档 https://d3js.org/d3-shape/area#area_defined
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
// 这里通过判断当前所遍历的值是否为 NaN 来判定该数据是否缺失
.defined(d => !isNaN(d))
// 设置下边界线横坐标读取函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,以返回该数据所对应的横坐标
// 这里基于当前所遍历的数据点的索引值,从数组 dates[i] 中读取出所对应的时间,并采用比例尺 x 进行映射,计算出相应的横坐标值
.x((d, i) => x(dates[i]))
// 设置下边界线的纵坐标的读取函数
// 所有系列的面积图的下边界线的初始定位都是 svg 的顶部,所以纵坐标值都是 0
.y0(0)
// 设置上边界线的纵坐标的读取函数,基于当前所遍历的数据点(车流量)并采用比例尺 z 进行映射,计算出相应的纵坐标值
.y1(d => z(d));
地平线图
下图演示了制作地平线图 Horizon chart 的 5 个步骤
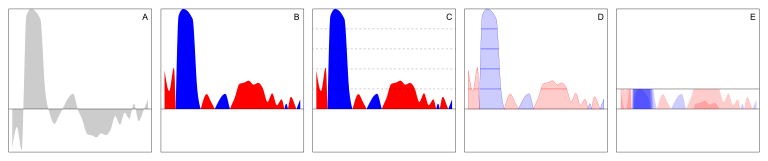
The figure illustrates the five steps involved in transforming an area chart into a horizon chart: A. Define a horizontal axis to differentiate positive values from negative values. 定义一个水平轴,以划分正负值 B. Reflect negative values above the axis, using blue for positive values and red for negative values. 将负值(关于水平轴)向上翻转,使用蓝色标记正值,使用红色标记负值 C. Divide the graph into distinct bands. 将面积图划分为多个等宽的条带 D. Adjust the opacity of the areas based on the number of subdivisions. 调整各个条带的透明度 E. Layer the obtained bands on top of each other to create the final horizon chart. 将上层条带依次往下堆叠,将普通的面积图转换为地平线图
参考自 Horizon chart - Wikipedia
另外还可以观看视频 What's a horizon chart and how to present one effectively 对于如何制作地平线图 Horizon chart 进行了更详细的介绍,并且介绍了地平线图的阅读方法,可以从中获取哪些信息
展示多系列数据的面积图对比
山脊线图与地平线图或面积图矩阵相比可以提供更高的精确度,要注意其前提是垂直空间有限
在绘图高度有限的前提下,上述三种可视化图形都可以展示多个数据,但采用的方式各不相同,所以可提供的精度也有差异:
- 面积图矩阵:通过将整体划分出多个小区域,就可以分别展示不同系列的数据,但是相应地每个小区域可展示的精度就变得更小了
- 山脊图:通过将多个面积图尽可能地重叠,以展示更多的系列数据,只要图形之间重叠部分足够大,就可以尽可能地降低对精度的影响(虽然会有可能出现由于重叠遮盖,而无法准确显示一些较低的数值)
- 地平线图:通过对面积图横向切片分段,再将切片重叠在一起,从而控制各个面积图的纵向高度(到相同的高度),但是这种处理方式会掩盖掉面积图的真实高度,为了弥补这个缺点需要为面积图添加颜色和设置透明度,以颜色的深浅来编码面积的高低。这样的转换会显著地降低精度(颜色深浅相对更难定量),但是很适合在有限的空间展示大量不同系列的数据,颜色也可以让读者对各系列数据之间的差异有更快速和直观的感受
地平线图的优势
由于地平线图是将面积图划分为多个条带后堆叠起来所构成的,所以地平线图还保留了原来面积图的分布走向,因此与单纯用颜色深浅表示数值大小的其他可视化图表相比,地平线图可以提供更多的信息
参考
- 解读的官方样例为 Horizon chart
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
绘制地平线图的关键是如何对面积图横向切片分段,再将切片重叠在一起
在以上示例通过元素 <use> 复用 svg 元素,可以很方便地在页面渲染出多个相同的面积图,然后利用元素 <clipPath> 的裁剪/约束视口功能,实现对面积图的切片效果,相关代码如下:
/**
*
* 绘制地平线图
*
*/
// 使用 d3.area() 创建一个面积生成器,它适用于生成各个系列的(未折叠)面积图
// 面积生成器会基于给定的数据生成面积形状
// 调用面积生成器时返回的结果,会基于生成器是否设置了画布上下文 context 而不同。如果设置了画布上下文 context,则生成一系列在画布上绘制路径的方法,通过调用它们可以将路径绘制到画布上;如果没有设置画布上下文 context,则生成字符串,可以作为 `<path>` 元素的属性 `d` 的值
// 具体可以参考官方文档 https://d3js.org/d3-shape/area
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
const area = d3.area()
// 💡 调用面积生成器方法 area.defined() 设置数据完整性检验函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,返回布尔值,以判断该元素的数据是否完整
// 该函数传入三个入参,当前的元素 `d`,该元素在数组中的索引 `i`,整个数组 `data`
// 当函数返回 true 时,面积生成器就会执行下一步(调用坐标读取函数),最后生成该元素相应的坐标数据
// 当函数返回 false 时,该元素就会就会跳过,当前面积就会截止,并在下一个有定义的元素再开始绘制,反映在图上就是一个个分离的面积区块
// 具体可以参考官方文档 https://d3js.org/d3-shape/area#area_defined
// 或这一篇笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-shape#面积生成器-areas
// 这里通过判断当前所遍历的值是否为 NaN 来判定该数据是否缺失
.defined(d => !isNaN(d.value))
// 设置下边界线横坐标读取函数
// 该函数会在调用面积生成器时,为数组中的每一个元素都执行一次,以返回该数据所对应的横坐标
// 这里基于当前所遍历的数据点的属性 d.date,并采用比例尺 x 进行映射,计算出相应的横坐标值
.x((d) => x(d.date))
// 设置下边界线的纵坐标的读取函数
// 所有系列的面积图的下边界线的初始定位都是 svg 的顶部往下一个带宽的高度(这样面积图「折叠」后都位于 svg 的顶部,便于之后将各系列面积图的重定位),所以纵坐标值都是 size
.y0(size)
// 设置(未折叠的面积图)上边界线的纵坐标的读取函数,基于当前所遍历的数据点的属性 d.value(车流量)并采用比例尺 y 进行映射,计算出相应的纵坐标值
.y1((d) => y(d.value));
// 创建一个 identifier 唯一标识符(字符串)
// 它会作为一些 svg 元素(例如 <path> 和 <clipPath> 元素)的 id 属性值的一部分(方便其他元素基于 id 来使用),以避免与其他元素发生冲突
// 这个字符串以 `o-` 为前缀
// 字符串的后半部分使用 JS 原生方法 Math.random() 生成一个在 (0,1) 之间的随机数,并使用方法 number.toString() 将该数字转换为字符串,最后使用 string.slice(2) 从字符串的第三位开始截取至末尾,即舍去了小数点及其前面的数字(零),所以 uid 的后半部分由数字 0 到 9 和字母 A 到 F 共 16 种符号随机组成而成的字符串
const uid = `O-${Math.random().toString(16).slice(2)}`;
console.log(uid)
// 创建容器
// 首先建一个整体的容器
const g = svg.append("g")
// 返回一个选择集,其中虚拟/占位元素是一系列的 <g> 元素,它们分别作为各个系列的容器
.selectAll("g")
.data(series) // 绑定数据,每个容器 <g> 元素对应一个系列的数据
.join("g") // 将这些 <g> 元素绘制到页面上
// 通过设置 CSS 的 transform 属性将各系列的容器定位不同的位置
// 各系列容器的纵坐标值是(它在数组 series 中的)索引值 i 乘上条带的高度 size,还要加上 marginTop(考虑 svg 顶部的留白)
.attr("transform", (d, i) => `translate(0,${i * size + marginTop})`);
// 💡 最后变量 g 是一个选择集,包含一系列的 `<g>` 元素,分别作为各个系列的面积图的容器
console.log(g);
// 在每个系列的容器 <g> 元素里分别添加 <defs> 元素
// 💡 在 <defs> 元素定义一些图形元素,以便之后使用(而不在当前渲染出来),一般通过元素 <use> 复用这些元素
const defs = g.append("defs");
// 💡 最后变量 defs 是一个选择集,包含一系列的 `<defs>` 元素(它们分别在各个系列的面积图的容器 <g> 里面)
// 在这些 <defs> 元素里分别定义一个 <clipPath> 元素和 <path> 元素
// ✂️ 其中元素 <clipPath>(一般具有属性 id 以便被其他元素引用)路径剪裁遮罩,其作用充当一层剪贴蒙版,具体形状由其包含的元素决定
// 这里在 <clipPath> 内部添加了一个 <rect> 设置剪裁路径的形状,让面积图约束在高度为 size 的矩形条带中
defs.append("clipPath")
// 为 <clipPath> 设置属性 id,其属性值使用前面生成的 uid 唯一标识符(字符串),并(使用连字符 `"-"`)拼接上字符串 `"clip"` 和索引值 i
.attr("id", (_, i) => `${uid}-clip-${i}`)
// 在其中添加 <rect> 子元素,以设置剪切路径的形状(将各个面积图约束在该矩形内)
.append("rect")
// 设置矩形的定位和尺寸,考虑各系列之间的间隔 padding
.attr("y", padding) // 设置纵坐标值(距离其容器顶部 padding 个像素大小,作为间隔相邻条带的空隙)
.attr("width", width) // 设置宽度(采用 svg 的宽度)
.attr("height", size - padding); // 设置高度(由于矩形纵坐标值为 padding,所以矩形的高度为 size - padding,这样每个条带的高度都可以保持为 size)
// ✒️ 而其中元素 <path> 路径用于绘制面积图
// 💡 将面积图定义在 <defs> 里便于复用,由于在地平线图里,每个条带都是由多个面积图堆叠而成的
defs.append("path")
// 为 <path> 设置属性 id,其属性值使用前面生成的 uid 唯一标识符(字符串),并(使用连字符 `"-"`)拼接上字符串 `"path"` 和索引值 i
.attr("id", (_, i) => `${uid}-path-${i}`)
// 由于面积生成器并没有调用方法 area.context(parentDOM) 设置画布上下文
// 所以调用面积生成器 area(values) 返回的结果是字符串
// 该值作为 `<path>` 元素的属性 `d` 的值
// 💡 在前面为每个系列容器绑定的数据是 series,它是一个 InternMap 对象
// 在绑定数据时 InternMap 对象会转换为数组(嵌套数组),其中每个元素都是以二元数组 [键名,值] 的形式表示
// 二元数组中,第一个元素对应于该系列名称,第二个元素是属于该系列的数据点(也是一个数组)
// 这里通过解构二元数组,获取第二个元素(即属于该系列的数据点),赋值给变量 values 以绘制该系列的面积图
.attr("d", ([, values]) => area(values));
// Create a group for each location, in which the reference area will be replicated
// (with the SVG:use element) for each band, and translated.
// 在每个系列的容器里分别添加一个 <g> 元素
g.append("g")
// 通过设置属性 clip-path 以采用在前面(<defs> 元素里)预设的 <clipPath> 元素,对该 <g> 元素里的图形元素进行裁剪,约束在高度为 size 的条带里
// 💡 这里属性 clip-path 的值也可以直接使用(<clipPath> 元素的 id 值)`#${uid}-clip-${i}`
.attr("clip-path", (_, i) => `url(${new URL(`#${uid}-clip-${i}`, location)})`)
// 进行二次选择,在 <g> 元素内添加多个 <use> 元素,以便通过重复引用在前面(<defs> 元素里)预设的 <path> 元素
.selectAll("use")
// ⚠️ 使用 select.selectAll() 所创建的新选择集会有多个分组
// 返回的选择集是由多个分组(各个系列容器里的 <g> 元素中)的虚拟/占位 <use> 元素构成的
// 由于新的选择集会创建多个分组,那么原来所绑定数据与(选择集中的)元素的对照关系会发生改变
// 从原来的一对一关系,变成了一对多关系,所以新的选择集中的元素**不会**自动「传递/继承」父节点所绑定的数据
// 所以如果要将原来选择集中所绑定的数据继续「传递」下去,就需要手动调用 selection.data() 方法,以显式声明要继续传递数据
// 在这种场景下,该方法的入参应该是一个返回数组的**函数**
// 每一个分组都会调用该方法,并依次传入三个参数:
// * 当前所遍历的分组的父节点所绑定的数据 datum
// * 当前所遍历的分组的索引 index
// * 选择集的所有父节点 parent nodes
// 详细介绍可以查看笔记 https://datavis-note.benbinbin.com/article/d3/core-concept/d3-concept-data-binding#绑定数据
// 这里所需要使用的是第二个参数 i(索引值,用于构建引用的 URL)
// 使用 JS 原生方法 new Array(bands) 手动构建出绑定的数据,该数组所含的元素数量是 bands,而且它们的值都是 i
.data((_ ,i) => new Array(bands).fill(i))
// 将 <use> 元素添加到页面上
.join("use")
// 最终在页面上(每个系列的容器中)添加了 bands 个 <use> 元素
// 为这些 <use> 元素设置属性 href,这里参数 i(并不是当前所遍历的 <use> 元素的索引值)是前面绑定的数据(即手动构建出来的数组),所以它表示该系列的索引值,即在同一个系列容器里这些 <use> 元素都是指向同一个 <path> 元素,绘制出相同的面积图
// 所以每个系列都会在页面以采用在前面(<defs> 元素里)预设的 <path> 元素,在页面上渲染出 bands 个(相同的)面积图
.attr("href", (i) => `${new URL(`#${uid}-path-${i}`, location)}`)
// 设置面积图的填充颜色,基于当前所遍历的元素的索引值,并采用颜色比例尺 colors 进行映射,得到该面积图所对应的颜色值 colors[i]
.attr("fill", (_, i) => colors[i])
// 再使用 CSS 的 transform 属性,基于索引值将这些面积图进行不同的纵向偏移 translate(0,${i * size}) 是条带高度 size 的倍数
// 💡 根据 svg 的坐标系统,左上角才是坐标 (0,0),而向右和向下是正方向(坐标值为正值),所以索引值越大,对应的面积图朝下的偏移量就越大
// 由于在前面为各个系列的容器设置了属性 clip-path,所以裁剪后视口高度只有 size 大小,则各个面积图只展示(不同的)一部分
.attr("transform", (_, i) => `translate(0,${i * size})`);
// 最终的效果相当于将面积图划分为 bands 个条带并堆叠在一起
实例
参考
- 解读的官方样例为 U.S. population by State, 1790–1990
- 对代码进行注释解读的 Notebook 是这个
- 复现可以查看该网页,完整代码可以查看 这里
该实例是一个标准化的堆叠式面积图,制作思路和核心代码类似
在为各个系列(堆叠面积)上添加标注文本信息所考虑的细节值得学习,首先是通过 <textPath> 元素让文本的延伸走向顺着面积形状,另外通过设置属性 startOffset 将文本定位在纵向空间较大的位置,相关代码如下
// 为每个系列添加文本标注
svg.append("g")
.style("font", "10px sans-serif") // 设置字体
.attr("text-anchor", "middle") // 设置文本对齐方式
// 使用 <text> 元素添加添加标注信息
.selectAll("text") // 返回一个选择集,其中虚拟/占位元素是一系列的 <text> 路径元素
.data(series) // 绑定数据,每个文本元素 <text> 对应一个系列数据
.join("text") // 将元素绘制到页面上
.attr("dy", "0.35em") // 设置文本在垂直方向上的偏移(让文本居中对齐)
// 在每个 <text> 元素里添加 <textPath> 元素(使用该元素包裹具体的文本内容),让文本沿着指定的路径放置
.append("textPath")
// 设置属性 href,采用所绑定数据的属性 d.id.href,指向前面在元素 <defs> 所创建的相应路径元素 <path>
// 所以每个系列的标注文本会沿着所在系列的中线延伸
.attr("href", d => `#${d.id}`)
// 设置文字距离路径开头多远(采用百分比)开始排布,让文本定位到(所在系列面积形状中)纵向空间较大的位置(如果在狭窄的位置放置文字,可能会与系列分界线重叠而影响可读性,文字还可能叠到在其他系列的面积上)
// 首先Math.max(0.05, Math.min(0.95, ...) 表示文字排布约束在距离路径的开头 5% 和 95% 区间中
// 其中最佳的放置点是在该系列上下界(同一个横坐标点)差距最大的地方,即 d3.maxIndex(d, d => d[1] - d[0]) 返回的索引值所对应的数据点,然后通过 d3.maxIndex(d, d => d[1] - d[0]) / (d.length - 1))) * 100}% 得到该数据点到路径的开头的距离占总路径的比例
.attr("startOffset", d => `${Math.max(0.05, Math.min(0.95, d.offset = d3.maxIndex(d, d => d[1] - d[0]) / (d.length - 1))) * 100}%`)
.text(d => d.key); // 设置文本内容
在为各个系列设置分隔线(上边界线)所考虑的细节也值得学习,该实例使用了 d3-color 模块,基于该系列的堆叠面积的填充颜色,计算出相应的更深的颜色作为分隔线(而不是简单地采用黑色),即保证了折现的可视性,同时又让可视化图整体看起来协调统一(采用同色系看起来更具美感),相关代码如下
/**
*
* 绘制面积图内的各系列(堆叠形状)之间的分隔线(上边界线)
*
*/
// 创建一个容器
svg.append("g")
// 只需要路径的描边作为折线,不需要填充,所以属性 fill 设置为 none
.attr("fill", "none")
.attr("stroke-width", 0.75) // 描边的宽度
// 使用路径 <path> 元素绘制折线
.selectAll("path") // 返回一个选择集,其中虚拟/占位元素是一系列的 <path> 路径元素,用于绘制各系列的边界线
.data(series) // 绑定数据,每个路径元素 <path> 对应一个系列数据
.join("path") // 将元素绘制到页面上
// 设置描边颜色
// 基于原来系列的填充色,采用一个更深的颜色
// 首先通过映射 regionByState.get(key) 获取当前系列表示的州所对应的区域,然后使用颜色比例尺 color() 获取相应的颜色
// 然后使用 d3.lab(color) 创建一个符合 CIELAB 色彩空间的颜色对象,具体参考官方文档 https://d3js.org/d3-color#lab
// 💡 该色彩空间旨在作为一个感知上统一的空间,更多介绍可以参考 https://en.wikipedia.org/wiki/CIELAB_color_space
// 最后使用 colorObj.darker() 基于原来的颜色得到一个更深的颜色
.attr("stroke", ({key}) => d3.lab(color(regionByState.get(key))).darker())
// 方法 area.lineY1() 返回一个线段生成器,用于在绘制面积图的上边界线
// 调用该线段生成器,返回的结果是字符串,该值作为 `<path>` 元素的属性 `d` 的值
.attr("d", area.lineY1());